

Why you need to care about the JDBC fetch size

Last week, Jeroen Borgers asked on Twitter for a standard way to set the JDBC fetch size in JPA, that is, for Hibernate’s Query.setFetchSize() to be added to the standard APIs. This took me slightly by surprise, because nobody has ever asked for that before, but I asked him to go ahead and open an issue. After some discussion, I think I’m satisfied that his actual needs can be met in a different way, but the discussion did help to draw my attention to something important: the default JDBC fetch size for the Oracle driver is 10.
Now, I would never pretend to be an expert in Oracle performance tuning, and I don’t use Oracle every day. Even so, I felt like this is something that I definitely should have known off the top of my head, after so many years working with JDBC.
Out of curiosity, I ran a poll on Twitter, which was shared by Franck Pachot among others:
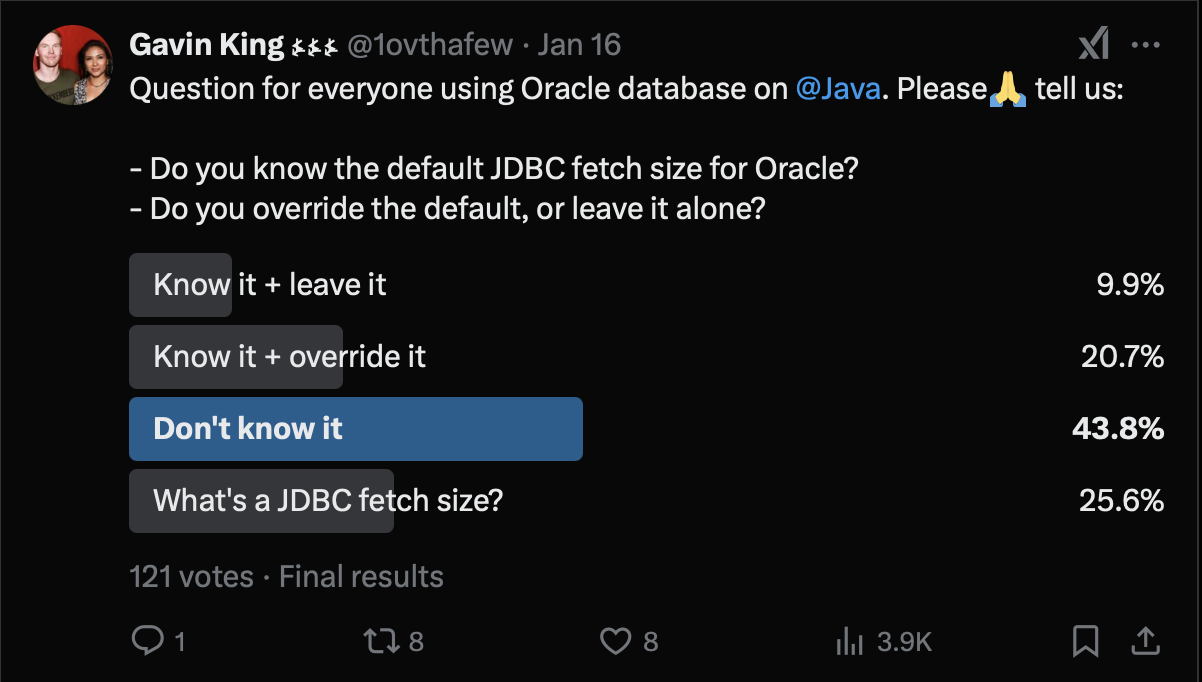
Now, look, N=121 is an okay sample size, but of course this was not a representative sample. So how would we expect this sample to skew compared to a typical random sample of developers? Well, I would like to think that my followers know quite a lot more about databases than most, and I’m even more confident in saying this about Franck’s followers.
But there’s another problem: I’m really interested in the responses of Oracle users, and I don’t know how many of the people who clicked "What’s a JDBC fetch size?" actually clicked it because I didn’t have room to add a "Just show me the results" option. In a lame attempt to compensate for this, I’m going to throw away all the people who claim to not know what a JDBC fetch size is, and focus on the remaining respondents.
Of those respondents, more than 70% claim to be using Oracle and are either unaware of the default fetch size, or know it, but don’t change it.
I got in contact with Loïc Lefèvre from Oracle to make sure that I fully understood the implications of this. He and his colleague Connor McDonald pointed out to me that actually the Oracle JDBC driver has an adaptive fetch size in the 23ai version, and that in the best case the driver will actually increase the fetch size to 250 on the fourth fetch, and that this behavior depends on the size of each row in the result set. Nice to know.
Alright, so, I’m going to make the following assertions upfront:
- Most Java data access code is doing online transaction processing, and not batch processing.
- For such programs, most queries return between 100 and 102 rows, with 103 rows being possible but already extremely rare. By contrast, 104 rows and above characterizes the offline batch processing case.
- The size of each row of such a query result set is not usually huge.
- Common practice—especially for programs using Hibernate or JPA—is to limit results using
LIMIT, read the whole JDBC result set immediately, putting the results into aListor whatever, and then carry on working with that list. - It’s common for the Java client to be on a different physical machine to the database server.
- It’s common for the Java client to have access to plentiful memory.
- The database server is typically the least scalable element of the system.
- For online transaction processing we care a lot about latency.
Of course one can easily concoct scenarios in which one or more of these assumptions is violated. Yes yes yes, I’m perfectly aware that some people do batch processing in Java. The comments I’m about to make do not apply to batch processing. But I insist that what I’ve described above is a fairly good description of the most common case.
Now consider what happens for a query returning 12 rows:
- On a first visit to the database server, the server executes the query, builds up the result set in memory, and then returns 10 rows to the client.
- The Java client iterates over those ten rows, hydrating a graph of Java objects, and putting them into a list or whatever, and then blocks waiting for the next 10 rows.
- The JDBC driver requests the remaining 2 rows from the server which has been keeping the result set waiting.
- The Java client can now process the remaining 2 rows, and finally carry on with what it was doing.
This is bad.
Not only did we make two trips to the server when one trip would have been better, we also forced the server to maintain client-associated state across an interaction. I repeat: the database server is typically the least scalable tier. We almost never want the database server to hold state while waiting around for the client to do stuff.
For a query which returns 50 rows, the story is even worse. Even in the best case, the default behavior of the driver requires four trips to the database to retrieve those 50 rows. Folks, a typical JVM is just not going to blow up with an OOME if you send it 50 rows at once!
So, my recommendations are as follows:
- The default JDBC fetch size should be set to a large number, somewhere between 103 and 231-1. This can be controlled via
hibernate.jdbc.fetch_size, or, even better, on Oracle, via thedefaultRowPrefetchJDBC connection property. Note that most JDBC drivers have an unlimited fetch size by default, and I believe that this is the best default. - Use pagination via a SQL
LIMIT, that is, the standard JPAsetMaxResults()API, to control the size of the result set if necessary. Remember: if you’re calling JPA’sgetResultList(), setting a smaller fetch size is not going to help control the amount of data retrieved at all, since the JPA provider is just going to eagerly read it all into a list anyway! - For special cases like batch processing of huge datasets, use
StatelessSessionorSession.clear()to control the use of memory on the Java side, andScrollableResultstogether withsetFetchSize()to control fetching. Or even better, just make life easy for yourself and write a damn stored procedure.
So if you belong to that 70% of Oracle users, you should be able to make your program more responsive and more scalable with almost no work, using this One Simple Trick.
Source: View source



