



Introduction
Artificial intelligence (AI) is central to Grab’s mission of delivering valuable, personalised experiences to millions of users across Southeast Asia. Achieving this requires a deep understanding of individual preferences, such as their favorite foods, relevant advertisements, spending habits, and more. This personalisation is driven by recommender models, which depend heavily on high-quality representations of the user.
Traditionally, these models have relied on hundreds to thousands of manually engineered features. Examples include the types of food ordered in the past week, the frequency of rides taken, or the average spending per transaction. However, these features were often highly specific to individual tasks, siloed within teams, and required substantial manual effort to create. Furthermore, they struggled to effectively capture time-series data, such as the sequence of user interactions with the app.
With advancements in learning from tabular and sequential data, Grab has developed a foundation model that addresses these limitations. By simultaneously learning from user interactions (clickstream data) and tabular data (e.g. transaction data), the model generates user embeddings that capture app behavior in a more holistic and generalised manner. These embeddings, represented as numerical values, serve as input features for downstream recommender models, enabling higher levels of personalisation and improved performance. Unlike manually engineered features, they generalise effectively across a wide range of tasks, including advertisement optimisation, dual app prediction, fraud detection, and churn probability, among others.
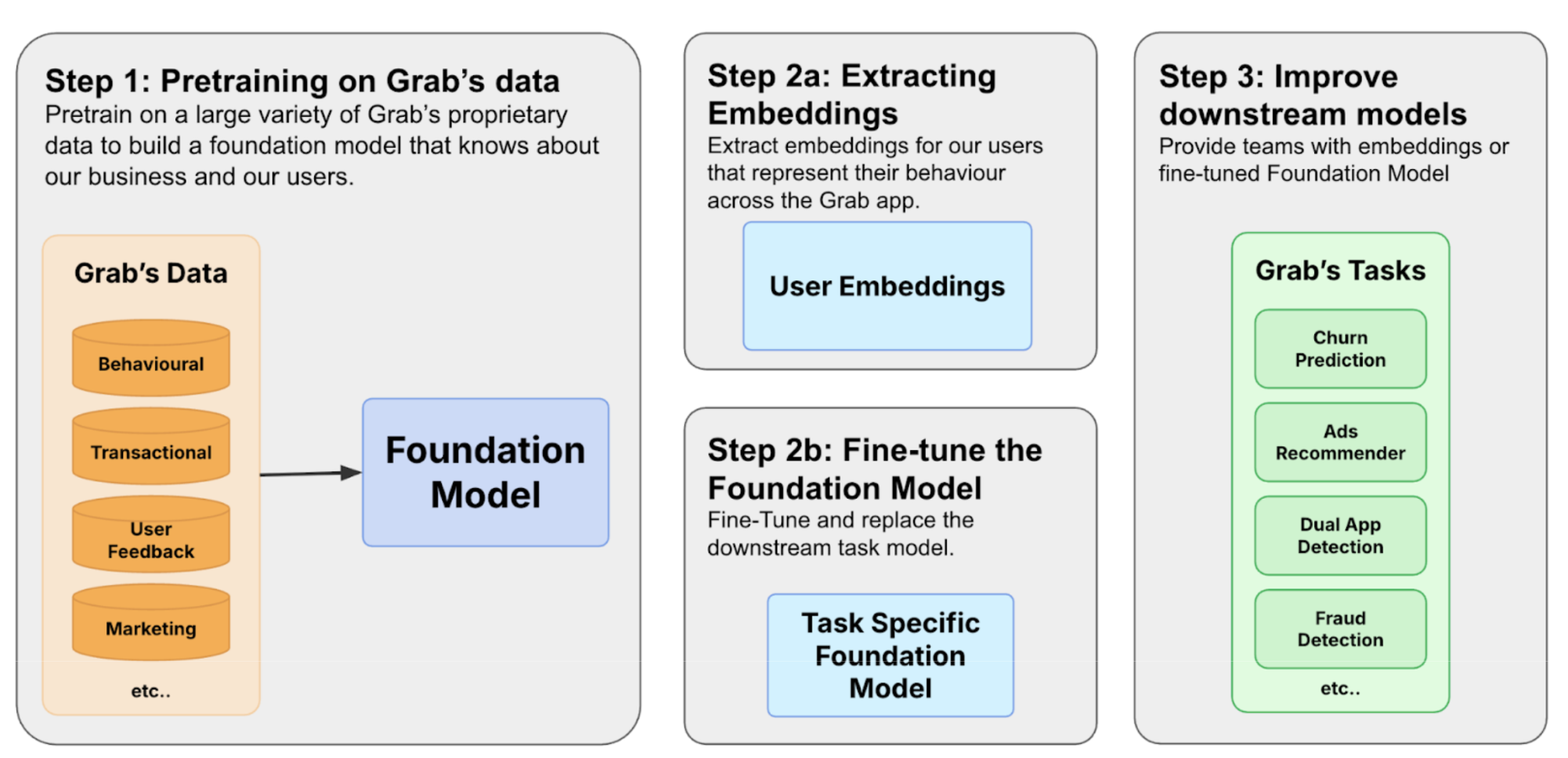
We build foundation models by first constructing a diverse training corpus encompassing user, merchant, and driver interactions. The pre-trained model can then be used in two ways. Based on Figure 1, in 2a we extract user embeddings from the model to serve downstream tasks to improve user understanding. The other path is 2b, where we fine-tune the model to make predictions directly.
Crafting a foundation model for Grab’s users
Grab’s journey towards building its own foundation model began with a clear recognition: existing models are not well-suited to our data. A general-purpose Large Language Model (LLM), for example, lacks the contextual understanding required to interpret why a specific geohash represents a bustling mall rather than a quiet residential area. Yet, this level of insight is precisely what we need for effective personalisation. This challenge extends beyond IDs, encompassing our entire ecosystem of text, numerical values, locations, and transactions.
Moreover, this rich data exists in two distinct forms: tabular data that captures a user’s long-term profile, and sequential time-series data that reflects their immediate intent. To truly understand our users, we needed a model capable of mastering both forms simultaneously. It became evident that off-the-shelf solutions would not suffice, prompting us to develop a custom foundation model tailored specifically to our users and their unique data.
The importance of data
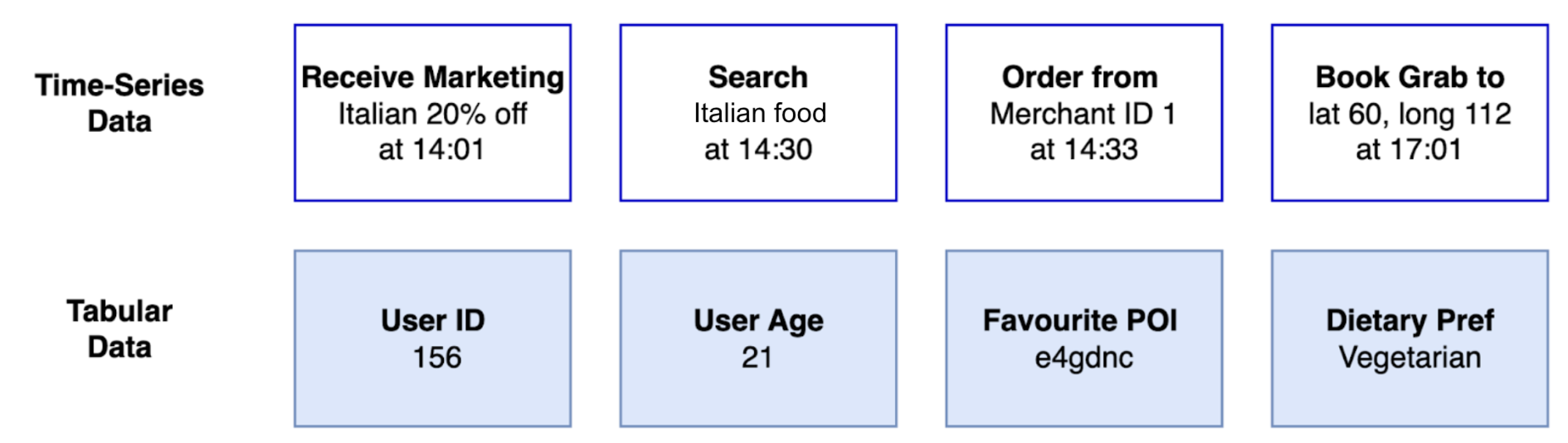
The success of foundation models hinges on the quality and diversity of the datasets used for training. Grab identified two essential sources of data for building user embeddings as shown in Figure 2. Tabular data provides general attributes and long-term behavior. Time-series data reflects how the user uses the app and captures the evolution of user preferences.
- Tabular data: This classic data source provides general user attributes and insights into long-term behavior. For example, this includes attributes like a user’s age and saved locations, along with aggregated behavioral data such as their average monthly spending or most frequently used service.
- Time-series clickstream data: Sequential data captures the dynamic nature of user decision-making and trends. Grab tracks every interaction on its app, including what users view, click, consider, and ultimately transact. Additionally, metrics like the duration between events reveal insights into user decisiveness. Time-series data provides a valuable perspective on evolving user preferences.
A successful user foundation model must be capable of integrating both tabular and time-series data. Adding to the complexity is the diversity of data modalities, including categorical/text, numerical, user IDs, images, and location data. Each modality carries unique information, often specific to Grab’s business, underscoring the need for a bespoke architecture.
This inherent diversity in data modalities distinguishes Grab from many other platforms. For example, a video recommendation platform primarily deals with a single modality: videos, supplemented by user interaction data such as watch history and ratings. Similarly, social media platforms are largely centred around posts, images, and videos. In contrast, Grab’s identity as a “superapp” generates a far broader spectrum of user actions and data types. As users navigate between ordering food, booking taxis, utilising courier services, and more, their interactions produce a rich and varied data trail that a successful model must be able to comprehend. Moreover, an effective foundation model for Grab must not only create embeddings for our users but also for our merchant-partners and driver-partners, each of whom brings their own distinctive sets of data modalities.
Examples of data modalities at Grab
To illustrate the breadth of data, consider these examples across different modalities:
- Text: This includes user-provided information such as search queries within GrabFood or GrabMart (“chicken rice,” “fresh milk”) and reviews or ratings for drivers and restaurants. For merchants, this could encompass the restaurant’s name, menu descriptions, and promotional texts.
- Numerical: This modality is rich with data points such as the price of a food order, the fare for a ride, the distance of a delivery, the waiting time for a driver, and the commission earned by a driver-partner. User behavior can also be quantified through numerical data, such as the frequency of app usage or average spending over a month.
- Merchant/User/Driver ID: These categorical identifiers are central to the platform. A
user_idtracks an individual’s activity across all of Grab’s services. Amerchant_idrepresents a specific restaurant or store, linking to its menu, location, and order history. Adriver_idcorresponds to a driver-partner, associated with their vehicle type, service area, and performance metrics. - Location data: Geographic information is fundamental to Grab’s operations. This includes airport locations, malls, pickup and drop-off points for a ride (
(lat_A, lon_A)to(lat_B, lon_B)), the delivery address for a food order, and the real-time location of drivers. This data helps in understanding user routines (e.g., commuting patterns) and logistical flows.
The challenges and opportunities of diverse modalities
The sheer variety of these data modalities presents several significant challenges and opportunities for building a unified user foundation model:
- Data heterogeneity: The different data types—text, numbers, geographical coordinates, and categorical IDs do not naturally lend themselves to being combined. Each modality has its own unique structure and requires specialised processing techniques before it can be integrated into a single model.
- Complex interactions as an opportunity: The relationships between different modalities are often intricate, revealing a user’s context and intent. A model that only sees one data type at a time will miss the full picture.
For example, consider a single user’s evening out. The journey begins when they book a ride (involving their user_id and a driver_id) to a specific drop-off point, such as a popular shopping mall (location data). Two hours later, from that same mall location, they open the app again and perform a search for “Japanese food” (text data). They then browse several restaurant profiles (merchant_ids) before placing an order, which includes a price (numerical data).
A traditional, siloed model would treat the ride and the food search as two independent events. However, the real opportunity lies in capturing the interactions within a single user’s journey. This is precisely what our unified foundation model is designed to achieve: to identify the connections and recognise that the drop-off location of a ride provides valuable context for a subsequent text search. A model that understands a location is not merely a coordinate, but a place that influences a user’s next action, can develop a far deeper understanding of user context. Unlocking this capability is the key to achieving superior performance in downstream tasks, such as personalisation.
Model architecture
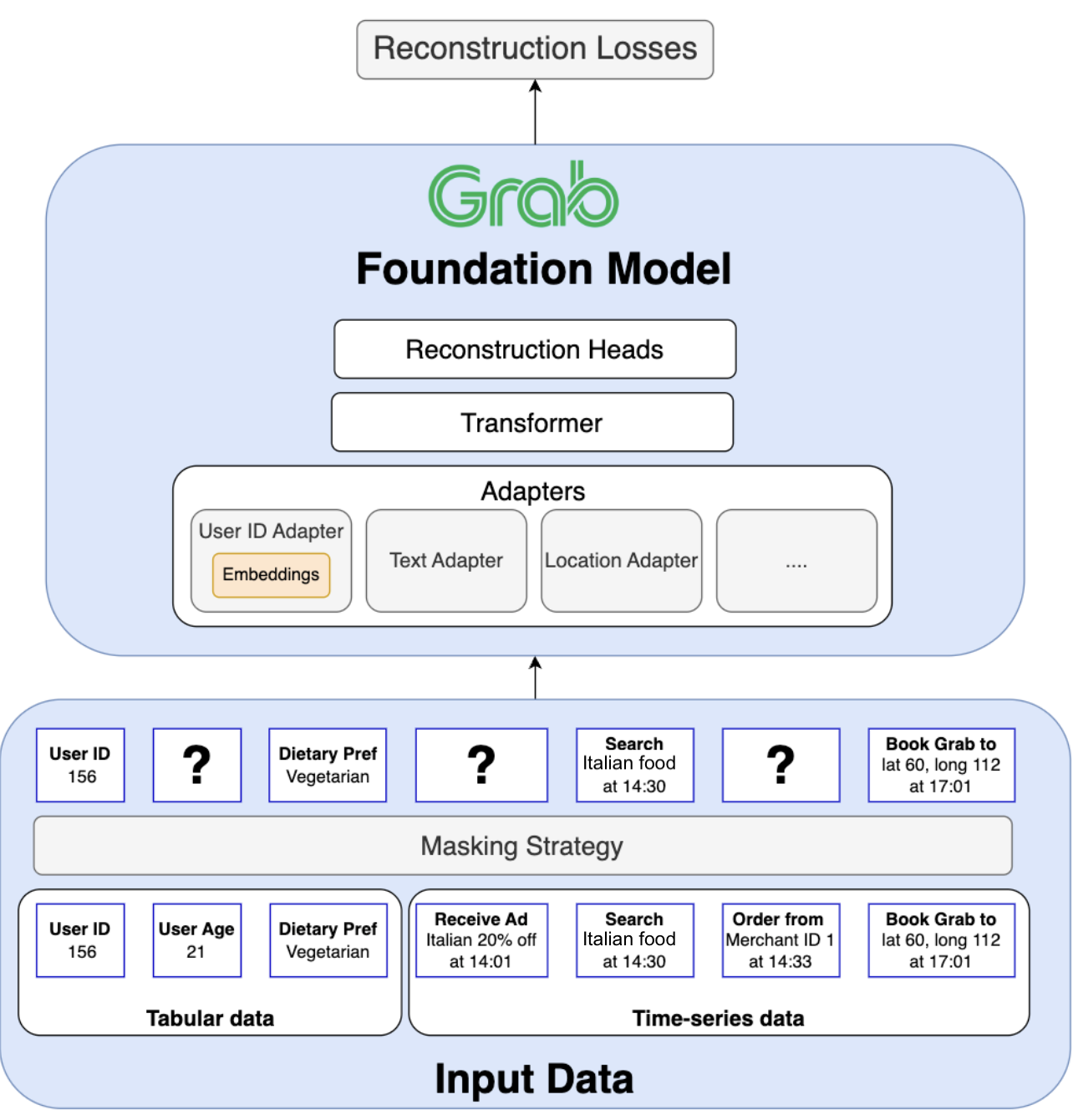
Figure 3 displays Grab’s transformer architecture, enabling joint pre-training on tabular and time-series data with different modalities. Grab’s foundation model is built on a transformer architecture specifically designed to tackle four fundamental challenges inherent to Grab’s superapp ecosystem:
- Jointly training on tabular and time-series data: A core requirement is to unify column order invariant tabular data (e.g. user attributes) with order-dependent time-series data (e.g. a sequence of user actions) within a single, coherent model.
- Handling a wide variety of data modalities: The model must process and integrate diverse data types, including text, numerical values, categorical IDs, and geographic locations, each requiring its own specialised encoding techniques.
- Generalising beyond a single task: The model must learn a universal representation from the entire ecosystem to power a wide array of downstream applications (e.g., recommendations, churn prediction, logistics) across all of Grab’s verticals.
- Scaling to massive entity vocabularies: The architecture must efficiently handle predictions across vocabularies containing hundreds of millions of unique entities (users, merchants, drivers), a scale that makes standard classification techniques computationally prohibitive.
In the following section, we highlight how we tackled each challenge.
1. Unifying tabular and time-series data
A key architectural challenge lies in jointly training on both tabular and time-series data. Tabular data, which contains user attributes, is inherently order-agnostic — the sequence of columns does not matter. In contrast, time-series data is order-dependent, as the sequence of user actions is critical for understanding intent and behavior.
Traditional approaches often process these data types separately or attempt to force tabular data into a sequential format. However, this can result in suboptimal representations, as the model may incorrectly infer meaning from the arbitrary order of columns.
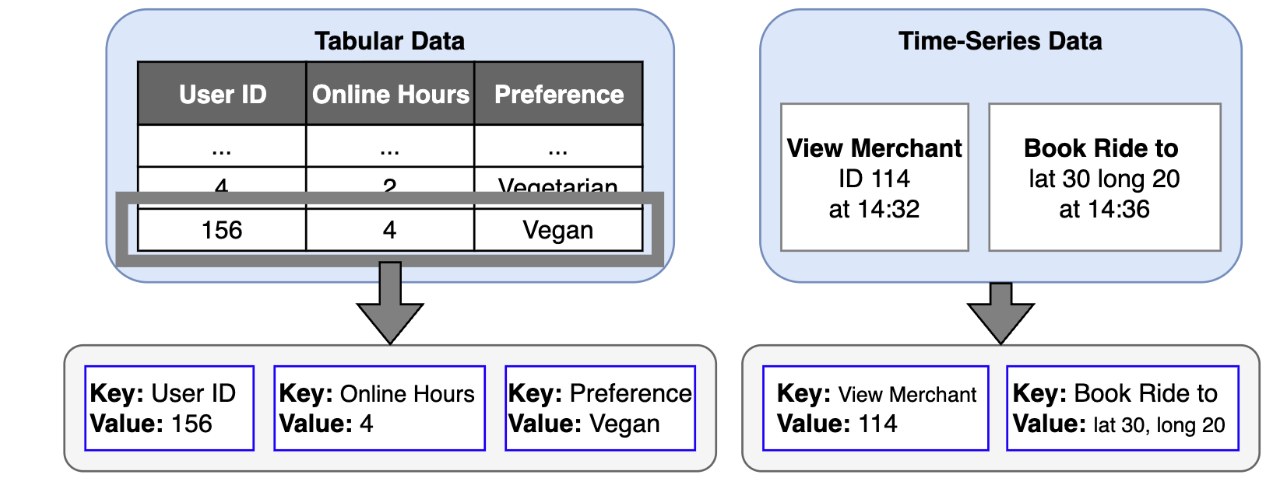
Our solution begins with a novel tokenisation strategy. We define a universal token structure as a key:value pair.
- For tabular data, the
keyis the column name (e.g.online_hours) and thevalueis the user’s attribute (e.g.4). - For time-series data, the
keyis the event type (e.g.view_merchant) and thevalueis the specific entity involved (e.g.merchant_id_114).
This key:value format creates a common language for all input data. To preserve the distinct nature of each data source, we employ custom positional embeddings and attention masks. These components instruct the model to treat key:value pairs from tabular data as an unordered set while treating tokens from time-series data as an ordered sequence. This allows the model to benefit from both data structures simultaneously within a single, coherent framework.
2. Handling diverse modalities with an adapter-based design
The second major challenge is the sheer variety of data modalities: user IDs, text, numerical values, locations, and more. To manage this diversity, our model uses a flexible adapter-based design. Each adapter acts as a specialised “expert” encoder for a specific modality, transforming its unique data format into a unified, high-dimensional vector space.
- For modalities like text, adapters can be initialised with powerful pre-trained language models to leverage their existing knowledge.
- For ID data like user/merchant/driver IDs, we initialise dedicated embedding layers.
- For complex and specialised data like location coordinates or not-so-well-modeled modalities like numbers in existing LLMs, we design custom adapters.
After each token passes through its corresponding modality adapter, an additional alignment layer ensures that all the resulting vectors are projected into the same representation space. This step is critical for allowing the model to compare and combine insights from different data types, for example, to understand the relationship between a text search query (“chicken rice”) and a location pin (a specific hawker center). Finally, we feed the aligned vectors into the main transformer model.
This modular adapter approach is highly scalable and future-proof, enabling us to easily incorporate new modalities like images or audio and upgrade individual components as more advanced architectures become available.
3. Unsupervised pre-training for a complex ecosystem
A powerful model architecture is only half the story; the learning strategy determines the quality and generality of the knowledge captured in the final embeddings.
In the industry, recommender models are often trained using a semi-supervised approach. A model is trained on a specific, supervised objective, such as predicting the next movie a user will watch or whether they will click on an ad. After this training, the internal embeddings, which now carry information fine-tuned for that one task, can be extracted and used for related applications. This method is highly effective for platforms with a relatively homogeneous primary task, like video recommendation or social media platforms.
However, this single-task approach is fundamentally misaligned with the needs of a superapp. At Grab, we need to power a vast and diverse set of downstream use cases, including food recommendations, ad targeting, transport optimisation, fraud detection, and churn prediction. Training a model solely on one of these objectives would create biased embeddings, limiting their utility for all other tasks. Furthermore, focusing on a single vertical like Food would mean ignoring the rich signals from a user’s activity in Transport, GrabMart, and Financial Services, preventing the model from forming a truly holistic understanding.
Our goal is to capture the complex and diverse interactions between our users, merchants, and drivers across all verticals. To achieve this, we concluded that unsupervised pre-training is the most effective path forward. This approach allows us to leverage the full breadth of data available, learning a universal representation of the entire Grab ecosystem without being constrained to a single predictive task.
To pre-train our model on tabular and time-series data, we combine masked language modeling (reconstructing randomly masked tokens) with next action prediction. On a superapp like Grab, a user’s journey is inherently unpredictable. A user might finish a ride and immediately search for a place to eat, or transition from browsing groceries on GrabMart to sending a package with GrabExpress. The next action could belong to any of our diverse services like mobility, deliveries, or financial services.
This ambiguity means the model faces a complex challenge: it’s not enough to predict which item a user might choose; it must first predict the type of interaction they will even initiate. Therefore, to capture the full complexity of user intent, our model performs a dual prediction that directly mirrors our key:value token structure:
- It predicts the type of the next action, such as
click_restaurant,book_ride, orsearch_mart. - It predicts the value associated with that action, like the specific restaurant ID, the destination coordinates, or the text of the search query.
This dual-prediction task forces the model to learn the intricate patterns of user behavior, creating a powerful foundation that can be extended across our entire platform. To handle these predictions, where the output could be of any modality (an ID, a location, text, etc.), we employ modality-specific reconstruction heads. Each head is designed for a particular data type and uses a tailored loss function (e.g. cross-entropy for categorical IDs, mean squared error for numerical values) to accurately evaluate the model’s predictions.
4. The ID reconstruction challenge
A significant challenge is the sheer scale of our categorical ID vocabularies. The total number of unique merchants, users, and drivers on the Grab platform runs into the hundreds of millions. A standard cross-entropy loss function would require a final prediction layer with a massive output dimension. For instance, a vocabulary

