




Fourteen years ago, Dropbox took its first steps toward building its own hardware infrastructure—and as our product and user base has grown, so has our infrastructure. What started with just a handful of servers has evolved into one of the largest custom-built storage systems in the world. We've scaled from a few dozen machines to tens of thousands of servers with millions of drives.
That evolution didn’t happen by accident. It took years of iteration, close collaboration with suppliers, and a product-first mindset that treated infrastructure as a strategic advantage. Now we’re excited to share what’s next: the launch of our seventh-generation hardware platform, now featuring Crush, Dexter, and Sonic for our traditional compute, database, and storage workloads, and our newest GPU tiers, Gumby and Godzilla. To make this leap possible, we dramatically increased storage bandwidth, effectively doubled our available rack power, and introduced a next-gen storage chassis designed to even further minimize vibration and heat.
This generation represents our most efficient, capable, and scalable architecture yet—and it’ll help us as we continue to build and scale helpful AI products like Dropbox Dash. Below, we’ll walk you through how we designed the latest version of our server hardware as well as key lessons we’ll carry into generations to come.

Dropbox Dash: Find anything. Protect everything.
Find, organize, and protect your work with Dropbox Dash. Now with advanced search for video and images—plus generative AI capabilities across even more connected apps.
Developing our strategy
To understand how we got to where we are today, it’s helpful to understand how we built the infrastructure foundation on which Dropbox runs. Back in 2015, we relocated all US customer data from off-premises hosts to on-site ones. The Magic Pocket team executed a massive migration project, bringing the bulk of Dropbox’s file storage into our own custom-built infrastructure. Over 90% of the roughly 600PB of data we stored at the time was moved into data centers we managed ourselves—a turning point that enabled better performance, cost control, and scale.
In the years following, we continued to grow—a lot. We ramped from 40PB of storage in 2012 to over 600PB by 2016. And today, we’re in our exabyte era, running on semi-custom hardware that we’ve designed to meet the unique needs of our platform. Along the way, we introduced new technologies such as SMR drives, which allow for higher storage density, and GPU accelerators for AI and compute-heavy tasks. And we’ve co-designed both hardware and software to serve our evolving workloads.
So, before committing to any designs for our seventh-generation server hardware, we set some high-level goals that drew from both what we’d learned from previous generations and opportunities from the latest hardware advancements in the industry. Three primary themes shaped our approach:
Embracing emerging tech
Infrastructure hardware is evolving fast. CPUs are getting more powerful with higher core counts and better performance per core. AI workloads are growing rapidly. Networks are moving toward faster speeds like 200G and 400G. And a new band of storage areal density has finally arrived. We used this moment to guide our strategy, aiming to harness these trends to improve our performance, efficiency, and scalability.
Partnering with suppliers
For this generation, we partnered closely with suppliers to co-develop storage platforms that fit our needs. This gave us early access to technologies like higher-density drives and high-performance controllers—along with the opportunity to help tune firmware for our specific workloads. These partnerships enabled the optimizations we needed to tackle the acoustic, vibration, and thermal challenges that come with dense system designs.
Strengthening these relationships also continues to give us a strategic edge: We get earlier access to emerging technology, deeper hardware customization, and a more stable platform.
Designing with software in mind
We brought in our software teams early to find out what would actually move the needle for their services. That led to goals like packing more compute power into each rack, enabling GPU support for AI and video processing, and improving speed and responsiveness for our database systems. Co-designing was a central theme; we weren’t just designing servers, but building platforms that elevated our services.
All of these goals converged around a central question: How big of a leap do we want to make, and what technologies will help get us there? Instead of maxing out everything just because we could, we focused on what matters most: better performance per watt, higher rack-level efficiency, and unlocking the right features to support our next chapter.

Dropbox seventh-generation hardware
A look under the hood of our next-gen hardware
Performance
The first big step in building our next-gen Dropbox server hardware was refreshing our CPUs. These do a lot more than crunch numbers. They shape the entire system’s platform, power use, cooling needs, and more—so picking the right ones really mattered. We started with a wide field of over 100 processors. To whittle this number down, our criteria required:
- Maximizing system throughput at the server and rack level
- Reducing latency of individual processes
- Improving price-performance for Dropbox workloads
- Ensuring balanced I/O and memory bandwidth
We ran tests using SPECintrate (a benchmark for multi-threaded workloads) and compared how each chip stacked up in performance per watt and per core. The CPU we picked stood out for both high throughput and strong per-core performance. It outperformed the previous generation by 40%.
Moving from our sixth-generation Cartman platform to the new Crush platform marked a big jump in compute power. At the heart of that upgrade was a shift from the 48-core AMD EPYC 7642 “Rome” processor to the 84-core AMD EPYC 9634 “Genoa.” This shift delivered some big gains:
- 75% more cores per socket (48 cores → 84 cores), improving bin packing for containerized services
- 2x the memory capacity (256GB → 512GB), boosting memory-heavy workloads
- DDR4 → DDR5, delivering higher bandwidth
- 25Gb → 100Gb networking, aligning with growing internal traffic
- NVMe gen5, speeding up local disk access and system boot times
We did all of this while keeping the same compact 1U “pizza box” server design, allowing 46 servers per rack, with no extra space needed.
Databases
On the database side, we focused on boosting CPU performance. While our new Dexter platform keeps the same number of cores as the previous generation, it packs a punch with 30% more instructions per cycle (IPC) and an increased base frequency (from 2.1GHz to 3.25GHz). The shift from dual-socket to single-socket design also reduced delays from inter-socket communication. These upgrades led to up to 3.57x less replication lag—the delay between when data is written to a primary system and when it’s copied to a secondary one—which made a huge difference for high-demand workloads like Dynovault and Edgestore.
Early on, we realized our database and compute platforms had a lot in common when it came to requirements. That opened the door for us to use the same platform from our system vendor for both. Consolidating like this helped us simplify our support stack, making it easier to manage components, firmware, drivers, and OS updates. The result was a versatile, dual-use platform that removed key scaling bottlenecks without sacrificing density or efficiency.
Storage
Finally, on the storage front, our design goals evolved to keep pace with increasing drive capacities. As drives get bigger—some now hold over 30TB—we had to think ahead. One of our internal performance standards is 30Gbps per PB of data. But with future systems expected to push past 100Gbps, we aimed even higher: 200Gbps throughput.
We also reworked our SAS topology to evenly allocate bandwidth to each drive and provide total system bandwidth past 200Gbps. And since this scale demanded stronger networking, we teamed up with our network engineering team to design a new 400G-ready data center architecture.
Thermal and power architecture
Upgrading to higher-core CPUs meant we had to rethink our approach to thermal and power management. Across the board, we saw power demands rise, so we needed a smarter way to stay within the limits of our existing data center infrastructure. First, we set a cap on processor thermal design power (TDP) to make sure we could pack in as many cores per rack as possible without blowing past our cooling or power budget.
Rather than taking worst-case “nameplate” power measurements—manufacturer-listed maximums that often overestimate real usage—we modeled real-world system usage. The models showed our servers could draw over 16kW per cabinet, which would’ve been a dealbreaker under our old 15kW per-rack power budget. To make it work without overhauling our entire power infrastructure, we teamed up with our data center engineering team and made a major change: We switched from two PDUs to four PDUs per rack, using existing busways and adding more receptacles.

Seventh-generation compute and storage (left); quad PDUs to meet higher power requirements (right)
This move effectively doubled our available rack power, giving us the breathing room to support current loads—and even future accelerator cards. Finally, we also worked closely with suppliers to improve airflow, upgrade heatsink designs, optimize fan curves, and test thermals under full-load conditions. It was a full-stack effort to keep things cool and efficient.
Focus on storage
Our storage strategy is all about getting more out of the same physical space. We’ve steadily increased the capacity of our traditional 3.5” hard drives from around 14TB to over 30TB in just a few years. This density improvement brings benefits: For one, it lowers cost per terabyte—and also reduces power usage per terabyte.
However, higher densities also heighten sensitivity to acoustic and vibrational interference. And for Dropbox, since over 99% of our storage fleet uses shingled magnetic recording (SMR) technology—which packs data in even tighter—the margin for error is razor-thin.
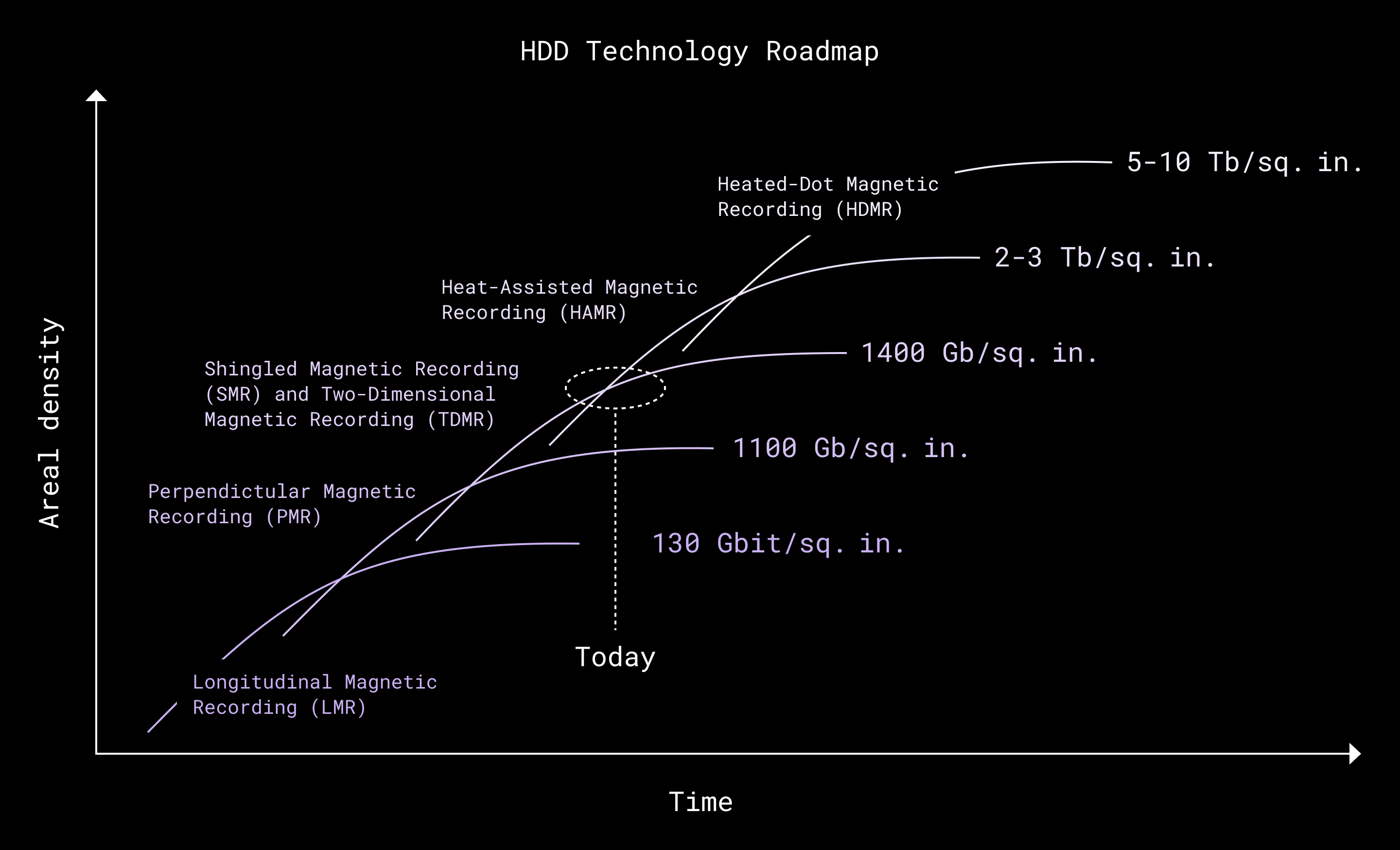
Dropbox continues to leap up to the next available areal density curve
Here’s the challenge: the read/write head inside these drives operates with nanometer precision. Even a tiny vibration can knock it off track. And when you’ve got fans spinning at over 10,000 RPM to cool a dense server, vibrations (and noise) can quickly stack up. That leads to something called a position error signal (PES)—and, in the worst case, a write fault that forces the drive to retry. That slows things down, increasing latency and reducing IOPS.
At the same time, we need that airflow to keep the drives cool. They operate best at around 40°C—and if things get too hot, drives age faster and error rates rise. This means we’re constantly balancing two opposing forces: cool enough to perform, quiet enough to be precise. To solve this, we co-developed our next-gen storage chassis with the system and drive suppliers. The key features we focused on were:
- Vibration control: Acoustical isolation and damping
- Thermals: Improved fan control and airflow redirection
- Future-proofing: Compatibility with the next generation of large-capacity drives
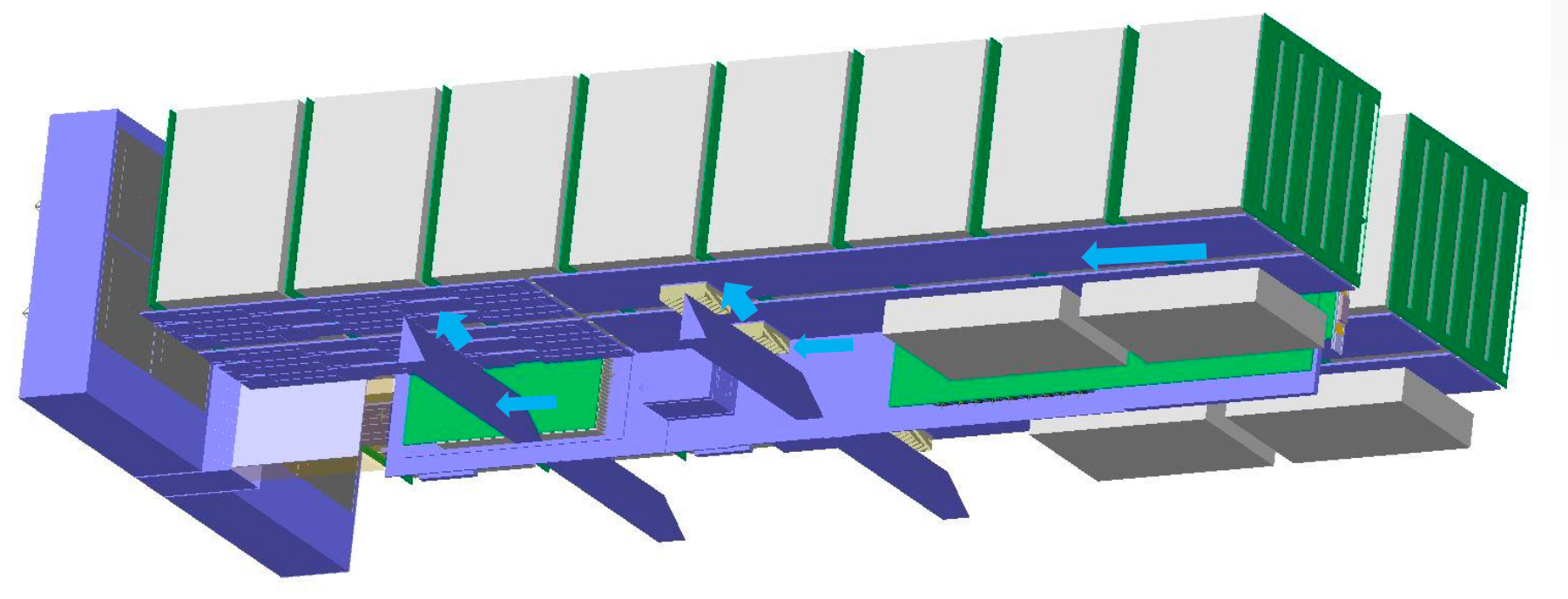
Redirecting high-velocity air to augment cooling
That work paid off. We were one of the first to adopt Western Digital’s Ultrastar HC690, which provides up to a 32TB SMR drive that fits 11 platters into a standard 3.5” casing. That’s more than a 10% bump in capacity compared to the last generation.
Leveling up with GPUs
To support Dash, our universal search and knowledge management product, it was clear we needed to bring GPUs into the mix. Features like intelligent previews, document understanding, fast search, and video processing (plus more recent work with large language models) all require serious computing muscle.
These workloads demand high parallelism, massive memory bandwidth, and low-latency interconnects—requirements that traditional CPU-based servers can’t economically support. So as part of our seventh-generation hardware rollout, we introduced two new GPU-enabled server tiers: Gumby and Godzilla.

GPU generations
- Gumby builds on our Crush compute platform but adds support for a wide range of GPU accelerators—hence the flexible name. It’s designed for flexibility, with support for TDPs ranging from 75W to 600W as well as both half-height half-length (HHHL) and full-height full-length (FHFL) PCIe form factors. Gumby is optimized for lightweight inference tasks like video transcoding, embedding generation, and other service-side machine learning enhancements.
- Godzilla is built for big jobs. It supports up to 8 interconnected GPUs, delivering the performance required for LLM testing, fine-tuning, and other high-throughput machine learning workflows.
Together, Gumby and Godzilla allow Dropbox to scale AI across our products while maintaining c

