




In the world of DevOps and Developer Experience (DevXP), speed and efficiency can make a big difference on an engineer’s day-to-day tasks. Today, we’ll dive into how Slack’s DevXP team took some existing tools and used them to optimize an end-to-end (E2E) testing pipeline. This lowered build times and reduced redundant processes, saving both time and resources for engineers at Slack.
The Problem: Unnecessary Frontend Builds
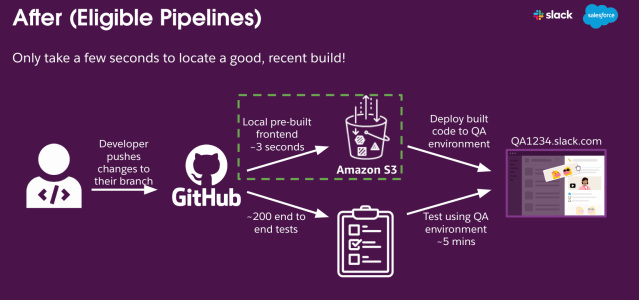
For one of our largest code repositories (a monolithic repository, or monorepo), Slack has a CI/CD pipeline that runs E2E tests before merging code into the main branch. This is critical for ensuring that changes are validated across the entire stack for the Slack application: frontend, backend, database, and the handful of services in between. However, we noticed a bottleneck: building the frontend code was taking longer than expected and occurred too frequently, even when there were no frontend-related changes. Here’s the breakdown:
- Developer Workflow: A developer makes changes and pushes to a branch.
- Build Process: The frontend code is built (~5 minutes).
- Deployment: The build is deployed to a QA environment.
- Testing: We run over 200 E2E tests, taking another 5 minutes.
This entire process took about 10 minutes per run. Half of that time, around 5 minutes, was consumed by frontend builds, even when no frontend changes were involved.

Given that hundreds of pull requests (PRs) are merged daily, these redundant builds were not only time-consuming, but costly:
- Thousands of frontend builds per week, storing nearly a gigabyte of data per build in AWS S3.
- Half of these builds do not contain frontend changes compared to the last merge into
main, causing terabytes of duplicate data.
- Half of these builds do not contain frontend changes compared to the last merge into
- 5 minutes per build, adding unnecessary delays to pipelines (thousands of hours a week).
The Solution: Smarter Build Strategy with Cached Frontend Assets
To tackle this, we leveraged existing tools to rethink our build strategy.
Step 1: Conditional Frontend Builds
Our first step was determining whether a fresh frontend build was necessary. We detected changes by utilizing git diff and its 3-dot notation to identify the difference between the latest common commit of the current checked-out branch and main. If changes were detected, we invoke a frontend build job. If no changes were detected, we skipped the build entirely and reused a prebuilt version.
Step 2: Prebuilt Assets and Internal CDN
When a frontend build is not needed, we locate an existing build from AWS S3. To be efficient, we use a recent frontend build that is still in Production. We delegate the task of serving the prebuilt frontend assets for our E2E tests to an internal CDN. This reduced the need for creating a new build on each PR, while still ensuring we test on current assets.
The Challenges: Efficiency at Scale
While the approach seemed straightforward, scaling this solution to our monorepo presented a few challenges:
- Identifying Frontend Changes: Our repository contains over 100,000 tracked files. Determining whether frontend changes were present required efficient file tracking, which git handled in just a couple of seconds.
- Finding Prebuilt Assets: With hundreds of PRs merged into this repository daily, identifying a prebuilt version that was fresh enough required robust asset management. By using straightforward S3 storage concepts, we were able to balance recency, coherent file naming, and performance to manage our assets.
- Being Fast: We were able to distinguish if a frontend build was unnecessary and find a recent build artifact in just under 3 seconds on average.
The Results: A 60% Drop in Build Frequency and 50% Drop in Build Time
Our efforts paid off, delivering remarkable improvements:
- 60% Reduction in Build Frequency: By intelligently reusing prebuilt frontend assets, we reduced the number of unnecessary frontend builds by over half.
- Hundreds of Hours Saved Monthly: Cloud compute time and developer wait times are reduced.
- Several Terabytes of Storage Savings: We reduced our AWS S3 storage by several terabytes each month. These duplicate assets would have otherwise been stored for one year.
- 50% Build Time Improvement: This was the second major project by the Frontend DevXP Team and its partnering teams. The first project, which upgraded our Webpack setup, reduced the average build from ~10 minutes to ~5 minutes. This project took the average build from ~5 minutes down to just ~2 minutes. With both projects being successful, we reduced our average build time for E2E pipelines from ~10 minutes to ~2 minutes: a huge improvement for the year!

Two unexpected outcomes:
- More Reliable and Trustworthy E2E Results: Our test flakiness, which refers to tests failing intermittently or inconsistently despite no code changes, was significantly reduced. This improvement resulted from the optimized pipeline, decreased likelihood of needing complex frontend builds, and consistent asset delivery. We observed our lowest percentage of test flakiness as a result.
- Rediscovering Legacy Code: Implementing this optimization required a deep dive into legacy code of multiple systems that hadn’t been significantly modified in a long time. This exploration yielded valuable insights, prompted new questions about the codebase’s behavior, and generated a backlog of tasks for future enhancements.
Conclusion: Rethinking Frontend Build Efficiency
By strategically utilizing existing tools like git diff and internal CDNs, we managed to save valuable developer time, reduce cloud costs, and improve overall build efficiency.
For teams in other companies facing similar bottlenecks in DevOps and DevXP, the lesson is to question what’s truly necessary in your pipeline and optimize accordingly. The improvement from this project seems obvious in hind-sight, but it’s common to overlook inefficiencies in systems that haven’t outright failed. In our case, rethinking how we handled frontend assets turned into a massive win for the organization.
Acknowledgments
There are a lot of moving parts in a project like this: complex pipelines for building and testing, cloud infrastructure, an internal CDN, intricate build systems for frontend code, and existing custom setups throughout our entire system. It includes code written in Python, JavaScript, Bash, PHP/Hack, Rust, YAML, and Ruby. We achieved this without any downtime! Okay, almost. There was ten minutes of downtime, but it was fixed pretty quickly.
This work was not possible without contributions from:
Anirudh Janga, Josh Cartmell, Arminé Iradian, Anupama Jasthi, Matt Jennings, Zack Weeden, John Long, Issac Gerges, Andrew MacDonald, Vani Anantha and Dave Harrington
Interested in taking on interesting projects, making people’s work lives easier, or just building some pretty cool forms? We’re hiring!
The post Optimizing Our E2E Pipeline appeared first on Engineering at Slack.