




Introduction
Catwalk is Grab’s machine learning (ML) model serving platform, designed to enable data scientists and engineers in deploying production-ready inference APIs. Currently, Catwalk powers hundreds of ML models and online deployments. To accommodate this growth, the platform has adapted to the rapidly evolving machine learning technology landscape. This involved progressively integrating support for multiple frameworks such as ONNX, PyTorch, TensorFlow, and vLLM. While this approach initially worked for a limited number of frameworks, it soon became unsustainable as maintaining various inference engines, ensuring backward compatibility, and managing deprecated legacy components (such as the ONNX server) introduced significant technical debt. Over time, this resulted in degraded platform performance: with increased latency, reduced throughput, and escalating costs. These issues began to impact users, as larger models could no longer be served efficiently or cost-effectively by legacy components. Recognising the need for change, the team revisited the platform’s design to address these challenges.
Evaluation and implementation
After evaluating other industry-leading model serving platforms and studying best practices, we decided to conduct an in-depth analysis of NVIDIA Triton. Triton offers significant advantages as an inference engine, including:
- Multi-framework support: Compatibility with major ML frameworks, including ONNX, PyTorch, and TensorFlow, ensuring versatility and broad applicability.
- Unified inference interface: Provides a single, consistent API for various ML frameworks, simplifying user interaction and reducing overhead when switching between models or frameworks.
- Hardware optimisation: Optimised for NVIDIA GPUs, Triton delivers strong performance on CPU-only environments and specialised instances like AWS Inferentia.
- Up-to-date support: Continuously updated by upstream to support the latest optimisation and features from upstream ML frameworks, ensuring access to cutting-edge capabilities.
- Advanced inference features: Includes capabilities like dynamic batching and model ensembling (model pipelining), which enhances throughput and efficiency for complex ML workflows.
Our extensive benchmarking demonstrated that NVIDIA Triton delivers substantial enhancements in both performance and service stability compared to our existing solutions.
We are now working towards consolidating the various inference engines we manage into a unified, all-in-one Triton engine, beginning with ONNX adoption as the first phase of implementation.
In this blog, we aim to share our journey of adopting Triton. From initial benchmarking results on one of Grab’s core models facing performance challenges, to the development of the “Triton manager”, a component designed to integrate Triton into our platform seamlessly and with minimal user disruption. Ultimately, more than 50% of online deployments were successfully migrated to Triton, with some of our critical systems achieving a 50% improvement in tail latency.
Exploratory benchmark results
We conducted rigorous testing of Triton against our existing ONNX server under varying levels of request traffic.
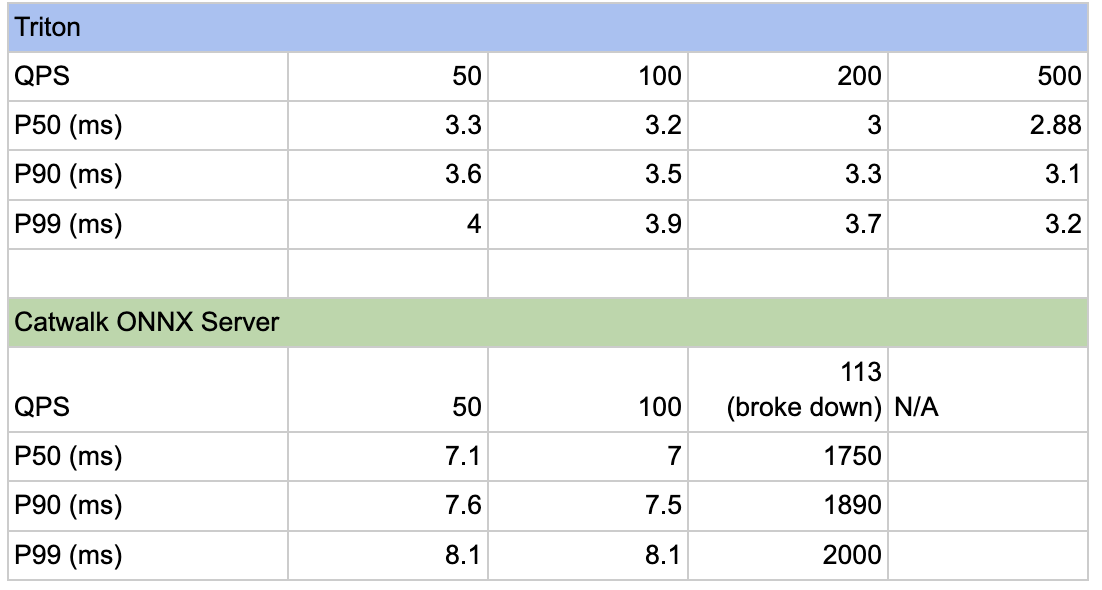
During testing with a transformer-based model, Triton demonstrated the ability to handle at least 5 times the traffic while maintaining excellent latency. Additionally, its performance was further enhanced with features like batching enabled, and there is potential for even greater optimisation by converting the model to TensorRT, leveraging GPU support.
Through profiling, we learned that a handful of ONNX Runtime knobs have an outsized impact on throughput. One low-effort, high-return tweak is to set the intra-op thread count to match the number of physical CPU cores. In most cases, this single change yields a healthy performance lift, sparing us from time-consuming, model-by-model micro-optimisation.
Adopting Triton at scale
While the benchmark results clearly demonstrate Triton’s advantages, the primary challenge was ensuring a seamless migration, ideally with minimal user reactions. Given the high frequency of migrations within our company, even exceptional performance improvements are often insufficient to fully motivate internal users to adopt new systems. From our point of view, a successful migration required:
- Maintaining API compatibility with existing systems.
- Ensuring zero-downtime.
- Preserving all existing functionality while adding new capabilities.
- Minimising disruption to downstream services and users.
To streamline the migration process, we opted to manage it centrally within our platform, rather than relying on individual users to address the details themselves.
We landed on the idea of offering Triton to our users as a drop-in replacement for the old server, with the help of a new component, “Triton manager”. The Triton manager is a critical component that glues Triton to the Catwalk ecosystem. It consists of two major components: Triton server manager and Triton proxy.
Triton server manager is designed as the entry point of our Catwalk Triton. It downloads the model from remote storage, runs verification on the model files, prepares per-model configurations based on users’ customisation, and lastly it launches the Triton server. It also periodically checks the server’s health and provides observability overlooking the server’s status.
Triton proxy provides backward compatibility to the existing clients. It hosts endpoints that translate requests from the older API and forward them to the Triton server. The proxy layer plays a crucial role in facilitating a seamless transition from our legacy servers, eliminating the need for user code changes. The conversion logic is designed to prioritise performance, ensuring minimal overhead. Extensive benchmarks were conducted during development to validate and optimise its efficiency.
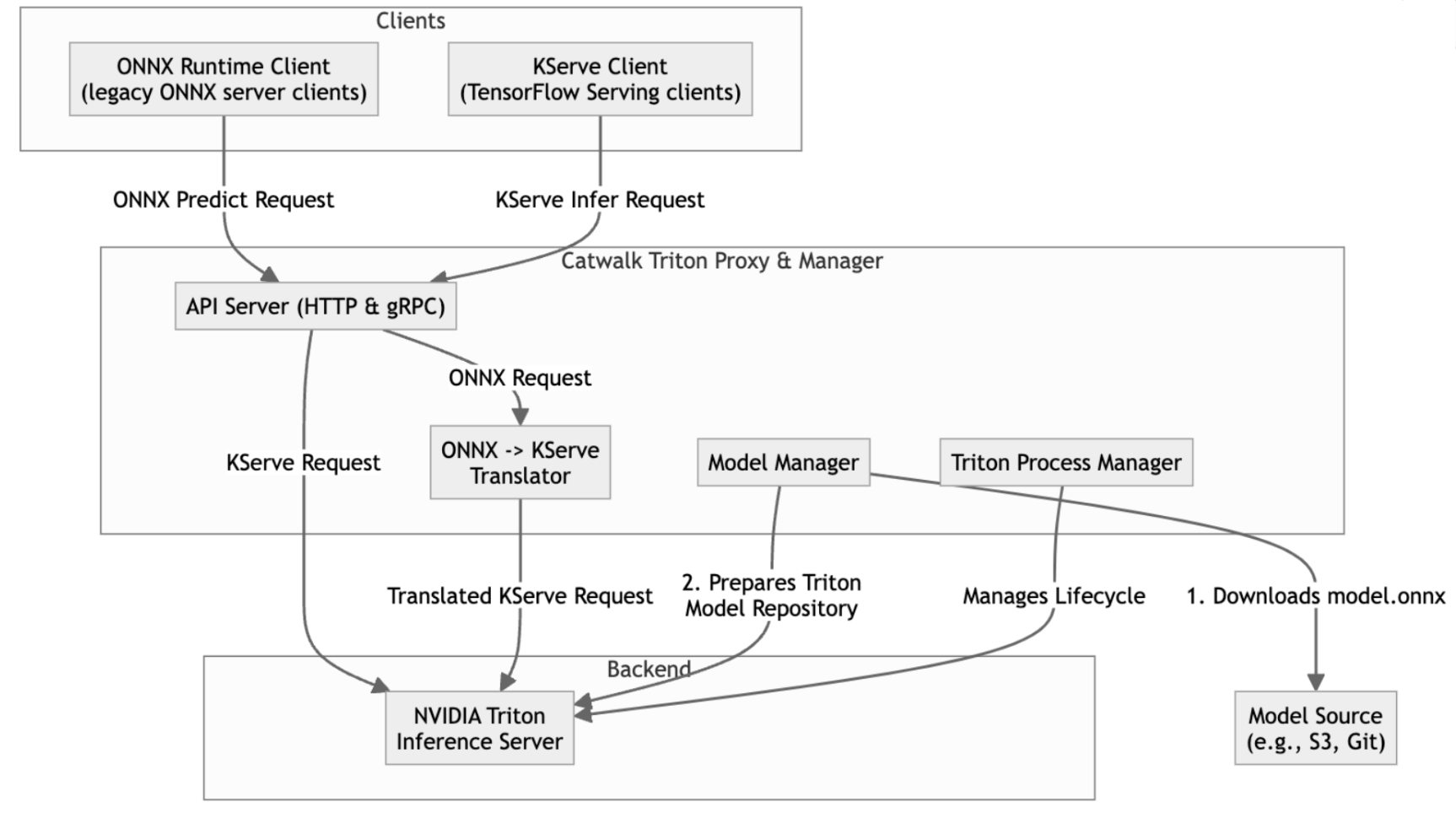
Finally, a special mode in the Triton server manager is implemented to allow the Triton Inference Server (TIS) to be backward compatible with the command line interface of the existing ONNX runtime server used in Catwalk.
We plan to enhance the Triton Manager to ensure backward compatibility with other ML frameworks, as part of our efforts to onboard additional frameworks seamlessly.
Rollout result
Within just 10 days of Triton’s availability, we successfully rolled it out to over 50% of our online model deployments. Thanks to rigorous testing for backward compatibility, the rollout was seamless, with most users unaware of the transition while benefiting from the improved performance.
Triton’s impacts on critical models
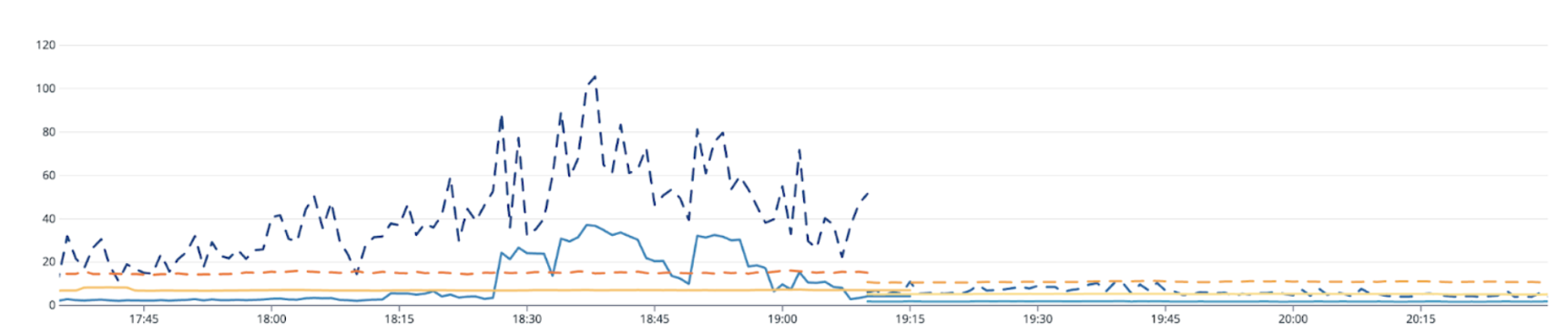
We’ve observed significant performance improvements in our business-critical models that have high demands for stability. Latency improvements were consistently observed in all models, especially in the models that suffered from highly volatile request traffic. For some larger transformer models, the p90 latency decreased dramatically from 120ms to 20ms, and the average latency remained steady at 4ms. Smaller XGBoost models maintained their average latency at 2ms across regions.
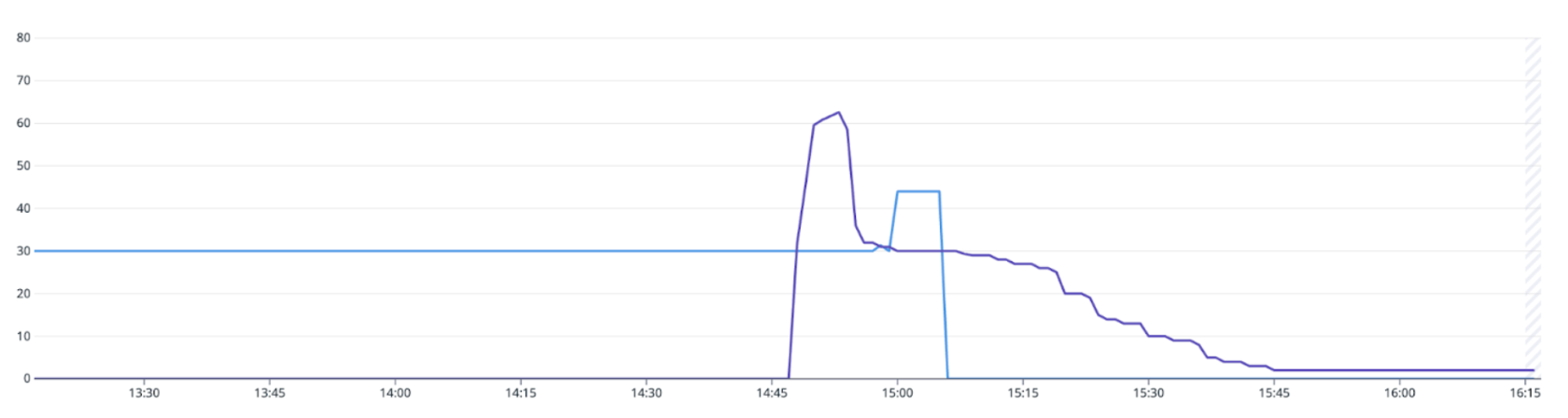
Triton has delivered significant cost savings for certain models, with some achieving over 90% reductions due to its advanced optimisations. These improvements have come alongside enhanced performance and reliability.
It is worth noting that Triton was initially rolled out with limited capabilities to prioritise backward compatibility and ensure a seamless migration. However, we’ve noticed that higher tail latency still remains an issue when facing request spikes for larger models in production. To address this, we are working on enabling batching through Triton to minimise tail latency during traffic surges. This effort will involve close collaboration with model owners to optimise the capacity of each Triton instance further.
Early cost impact of the migration
To gauge the financial upside of migrating to Triton, we took a snapshot of 11 production ML services that had already completed the migration. For every ML service, we compared its infrastructure spend over the 14 days before the cut-over with the 14 days after.
Despite the staggered migration dates, the trend was uniform: average spend fell by ~ 20% across this small cohort within 14 days. As more models and applications migrate, we expect the absolute dollar savings to scale proportionally.
Takeaways
Initial results are aligned with our benchmarks for the Triton migration. With improved performance and cost reduction, we expect model owners to either upgrade their model sizes or allow for higher Queries Per Second (QPS). While making further progress with the overall Triton migration, the model serving platform team will continue to monitor cost differences and provide consultation to model owners who seek further optimisation for their deployments.
Another key takeaway is the painless migration of Triton for our internal users. Rather than asking internal users to make necessary code changes, our team dedicated significant time to providing Triton as a drop-in inference engine to minimise any inconvenience of migration.
Big appreciation to Shengwei Pang from the Geo team, Khai Hung Do, Nhat Minh Nguyen, and Siddharth Pandey from the Catwalk team, along with Richard Ryu from the PM team and Padarn George Wilson for the sponsorship.
Join us
Grab is a leading superapp in Southeast Asia, operating across the deliveries, mobility and digital financial services sectors. Serving over 800 cities in eight Southeast Asian countries, Grab enables millions of people everyday to order food or groceries, send packages, hail a ride or taxi, pay for online purchases or access services such as lending and insurance, all through a single app. Grab was founded in 2012 with the mission to drive Southeast Asia forward by creating economic empowerment for everyone. Grab strives to serve a triple bottom line – we aim to simultaneously deliver financial performance for our shareholders and have a positive social impact, which includes economic empowerment for millions of people in the region, while mitigating our environmental footprint.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
