




Introduction
Ah, the familiar beep beep beep but don’t worry, it’s not your alarm coaxing you out of bed. No, this is far worse: the dreaded PagerDuty on-call alert! What’s the crisis this time? There appears to be an issue with high database CPU utilisation, overwhelmed by a flood of heavy traffic. If you’re a developer, chances are you’ve faced this scenario at least once. The very moment when you question every life decision while desperately searching for answers at 3 AM.
This article was born of one such heart-pounding, adrenaline-fuelled incident. Picture this: the database was struggling, the traffic was relentless, and the team was caught in the crossfire. The seemingly obvious solution was to migrate from SQL to NoSQL—a straightforward fix, or so it seemed. Instead of taking the easy way out, we stepped back, rolled up our sleeves, and tackled the problem head-on, embarking on a bold journey of optimisation.
What followed was a rollercoaster of trial, error, and a few “why did we even try this” moments. Yet, isn’t that the beauty of being a developer? Embracing the chaos, thriving in the madness, and eventually emerging victorious with a story worth sharing.
Real-time usage count tracking is a common use case that can be found across many applications, like Instagram’s post like count, YouTube’s watch count, or a marketing campaign usage count, which is used in monitoring and measuring the performance of marketing campaigns to assess effectiveness. These counts don’t have to be highly accurate, but rather an approximation in most use cases. This meant that in an occurrence of an event, instead of immediately updating the count in the database, the count is cached in the application server and later updated in batches to reduce the database Queries Per Second (QPS) and Central Processing Unit (CPU) utilisation.
This article shares one such use case where we optimised the campaign usage count tracking with highly concurrent in-memory caching that flushes to the database at periodic intervals.
Background
Marketing campaigns are configured to deliver push notifications, emails, and award rewards and points to Grab users. Total usage as well as daily usage needs to be tracked for display purposes to give a sense of how the campaign is performing. In this use case, accuracy is not a top priority. This release in constraint helps us to reduce write traffic by incrementing the counter in-memory and flushing the disk at periodic intervals for persistence.
In this section, let’s break down the process of designing a highly concurrent in-memory counter with data persistence.
Functional requirements
- Upsert the counter value for the given key.
- Periodically flush the counter value to the storage layer for persistence.
Non-functional requirements
Do note that although consistency is not critical for this use case, we will build a generic in-memory counter with the following guarantees, which can be reused for other use cases:
- Highly consistent updates of the counter values in memory during high concurrency.
- Consistent flushing of the counter values to the storage layer for persistence.
Simple GoLang code for writing an in-memory counter may look like the code sample shown in Figure 1.
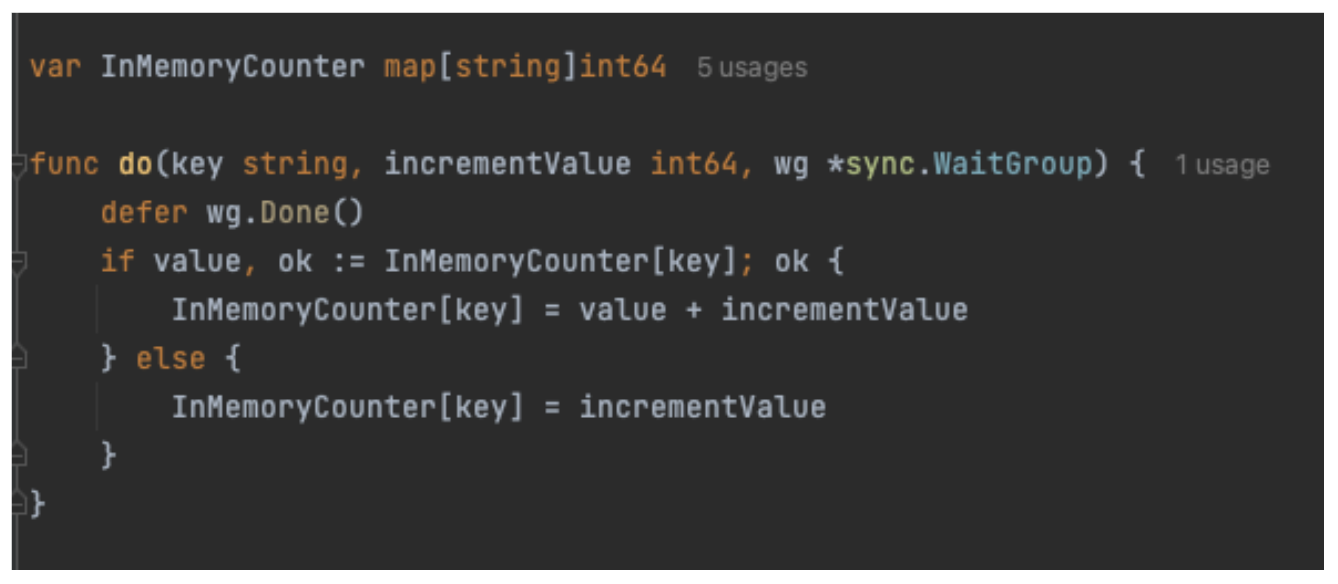
The code has a map declared globally, and the do function increments the counter value against the key. However, this code fails to work when multiple Goroutines (GoLang version of threads) try to access this do function concurrently. This will result in the following error, as shown in Figure 2.
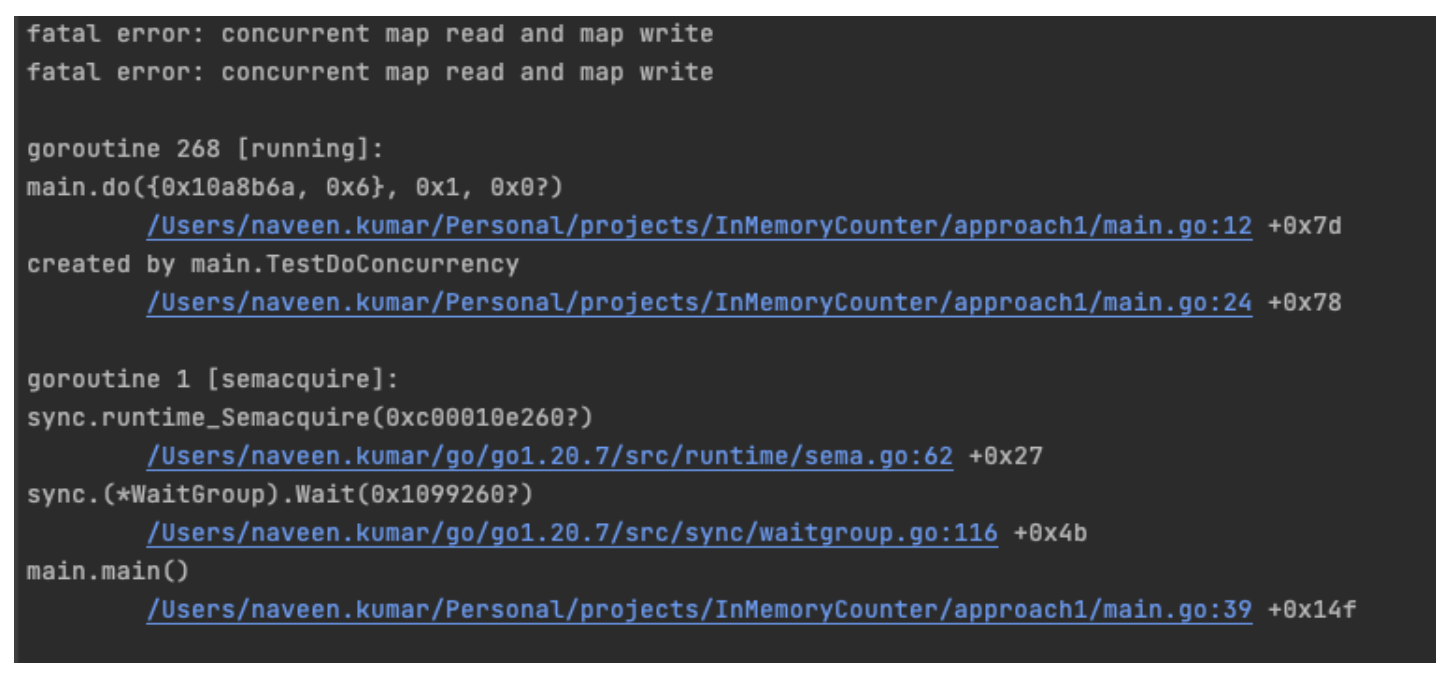
Maps in GoLang are not thread safe and need to be locked when being accessed concurrently. The GoLang sync package has Mutex, which serves this locking purpose. The code changes are shown in Figure 3. The sync.RWMutex object is declared globally and every time the do function is called, the lock is obtained first. Then the map is mutated, followed by releasing the lock at the end. This code works as intended even when multiple go routines try to access it concurrently.
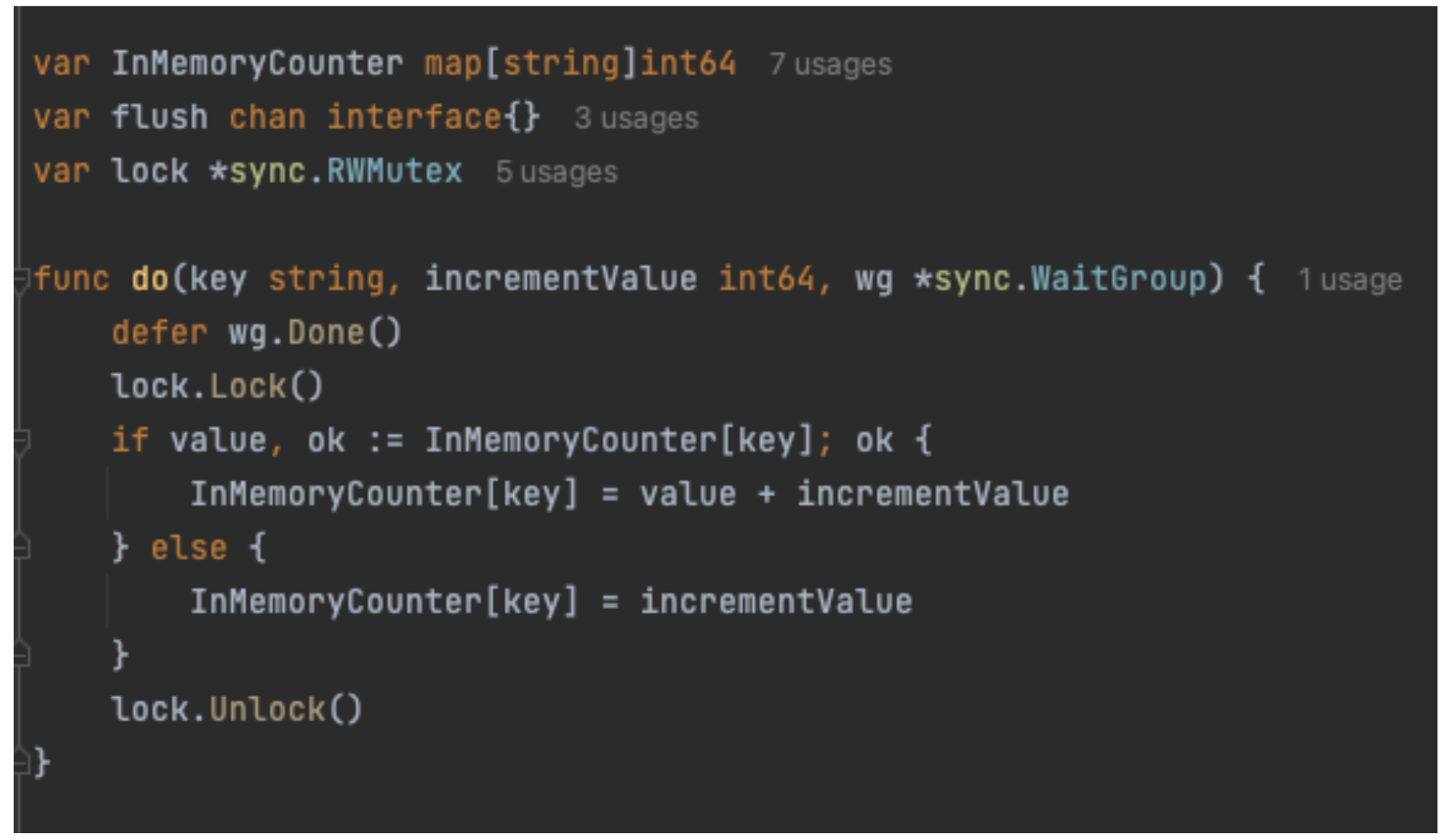
The code for the functional requirement of periodically flushing the counter value to the storage layer is shown in Figure 4.
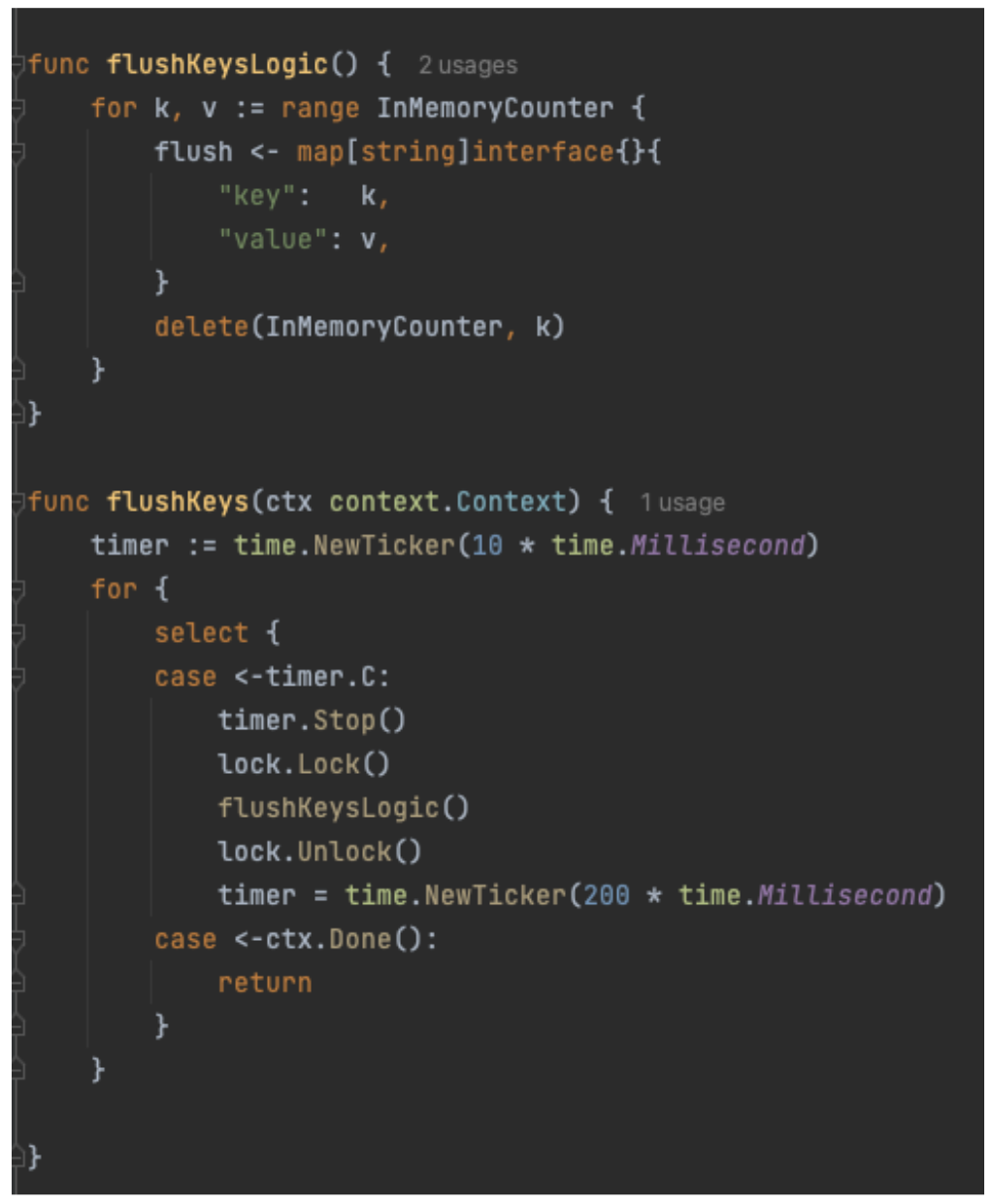
Assuming that this design is a success, every 200 milliseconds, a background job acquires a global map lock, iterates over all keys, writes each entry to the storage layer asynchronously, then deletes it from the map. After that, a flush is executed where counter increments are blocked until the lock is released.
Can we do something better?
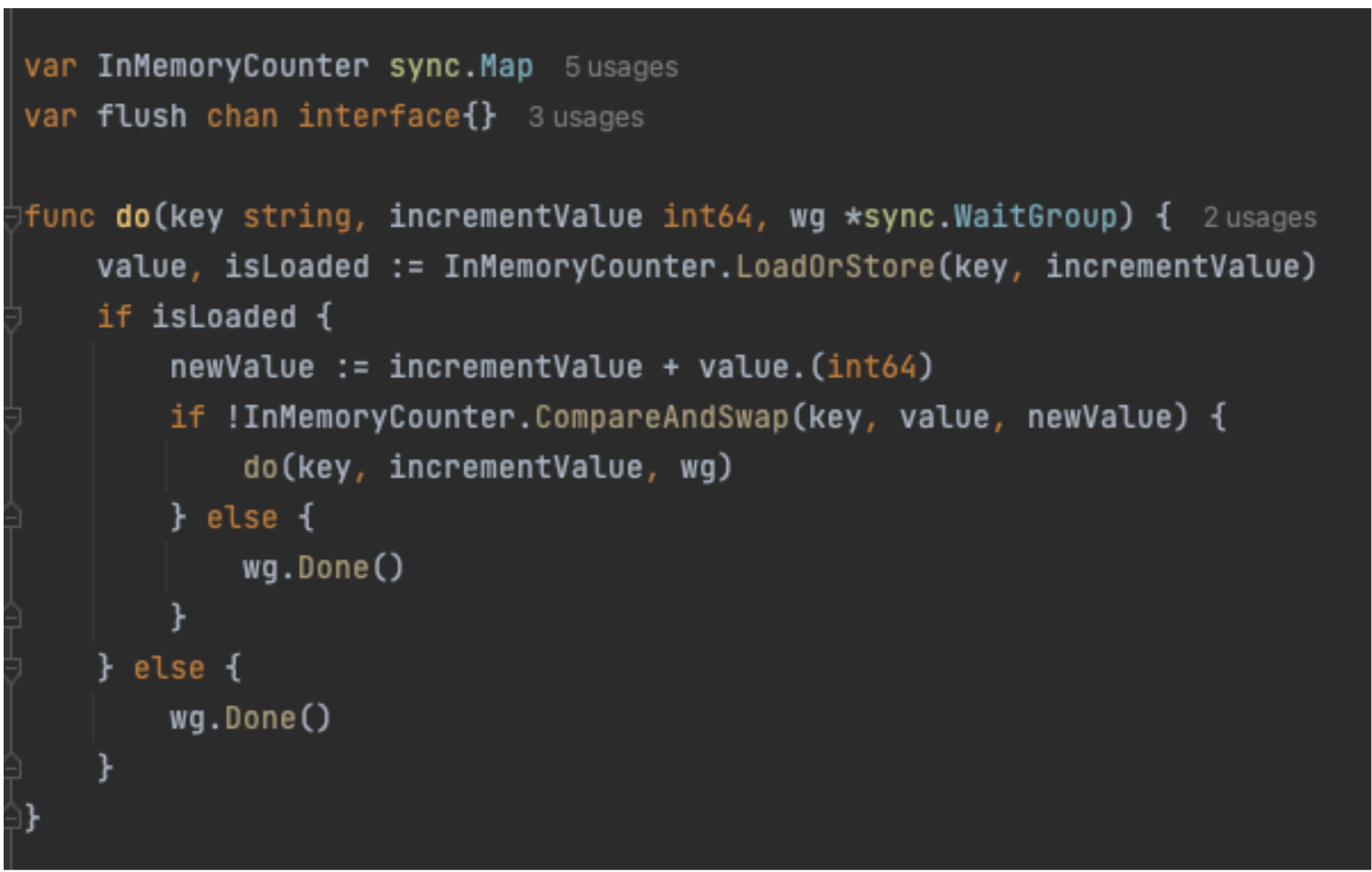
Yes, Sync.Map is the synchronised version of map in GoLang. This can be used to get rid of the explicit locking overheads.
Powerful features of the Sync.Map:
- LoadOrStore: Retrieves the existing value for a key if present, or stores and returns a new value if the key is absent. Ensuring atomic operation and preventing race conditions.
- CompareAndSwap: Atomically compares a variable’s current value to an expected value. If they match, it is swapped with a new value, ensuring thread-safe updates.
- LoadAndDelete: Atomically retrieves and removes the value of a given key, returning the value and a boolean indicating if the key was present.
When combined, these Sync.Map features produce the do function shown in Figure 5. When the do function is called, the LoadOrStore function tries to atomically store the key in the map if the key is absent. Otherwise, it returns the current value for the key with the isLoaded variable set to true. If the key is already present, a new value is created by summing up the increment value with the current value and setting it as the new value in the map using the CompareAndSwap function. The compareAndSwap function successfully sets the new value to the key only if the existing value in the map matches the current value. During high concurrency, this can fail, so we recursively retry until the CompareAndSwap replaces the current value with the new value.
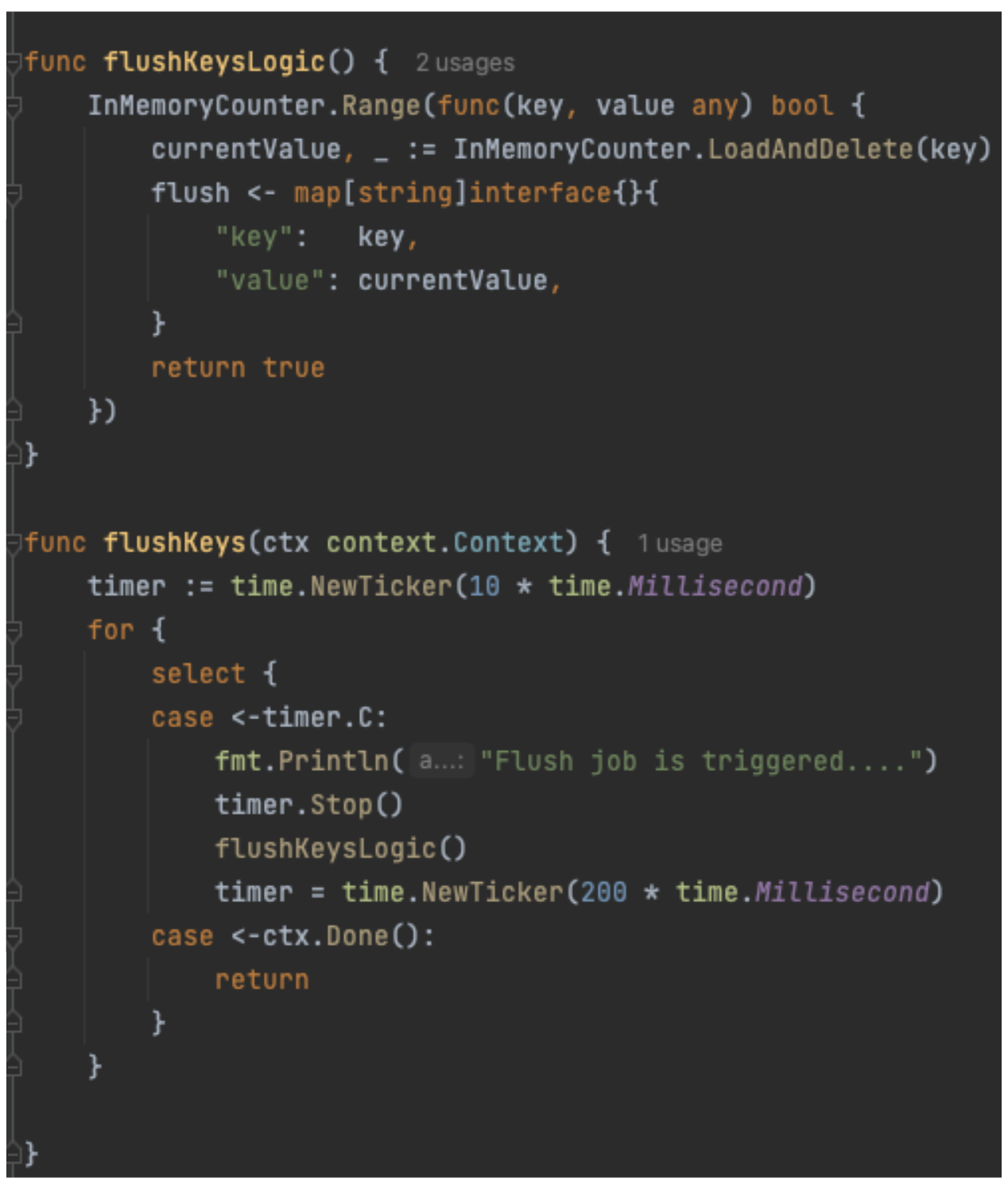
The code example for periodically flushing the counter value to the storage layer is shown in Figure 6. In the previous version of the code, it obtained the lock on the entire map and flushed the counter to the storage layer before releasing the lock. However, there is no locking during this flushing operation. Instead, we rely on the LoadAndDelete function to atomically remove a key from the map. This also returns the latest value for the key, which is updated into the storage layer async.
Benchmarking
An experiment was conducted on an Apple M1 16 GB RAM machine to test a use case of spawning a maximum of 200 million concurrent Goroutines to increment the counter of 40 keys. The results are:
- The approach of using a map with Mutex-based locking took 1 minute and 50 seconds across 5 runs.
- The approach of using
Sync.Mapwith atomic updates took 1 minute and 20 seconds across 5 runs.
In summary, getting rid of explicit locking with Sync.Map is ~30% faster than using Mutex to make the map thread safe.
Approach comparison
| Map with Mutex | Synchronised map (Sync.Map) |
|---|---|
| Locks are explicitly taken. | Implicit locks. |
| Experiment running averaged over 5 runs: 1 minute and 50 seconds | Experiment running averaged over 5 runs: 1 minute and 20 seconds |
| Time for operation increases linearly with more keys trying to update the counter, as the entire map is locked during update and flush operations. | Time for operation remains almost constant as the map is not locked. |
Conclusion
We implemented the Sync.Map approach for our in-memory counter that periodically flushes the campaign usage count in the database. This implementation resulted in the following efficiency improvements:
- 68% decrease in usage tracking update queries, nose-diving from 140 QPS to just 45 QPS!
- Master database experienced a significant reduction in CPU utilisation, decreasing by 48.5%—from 35% to just 18%, alleviating considerable strain on its resources.
- Replica databases benefited from a 37% decrease in CPU utilisation, dropping from 19% to a more manageable 12%.
Through this optimisation journey, we successfully overcame the challenging database CPU bottlenecks while avoiding the substantial effort and complexity of migrating from SQL to NoSQL. Who would have thought that a calculated leap of faith could save us so much time, effort, and countless sleepless nights? At times, the most effective solutions arise from taking a step back and approaching the problem with a fresh perspective, rather than rushing towards an immediate fix.
Join us
Grab is a leading superapp in Southeast Asia, operating across the deliveries, mobility and digital financial services sectors. Serving over 800 cities in eight Southeast Asian countries, Grab enables millions of people everyday to order food or groceries, send packages, hail a ride or taxi, pay for online purchases or access services such as lending and insurance, all through a single app. Grab was founded in 2012 with the mission to drive Southeast Asia forward by creating economic empowerment for everyone. Grab strives to serve a triple bottom line – we aim to simultaneously deliver financial performance for our shareholders and have a positive social impact, which includes economic empowerment for millions of people in the region, while mitigating our environmental footprint.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
