




Enter Deliveroo’s ML Platform
For the past three years, we have been building Deliveroo’s Machine Learning Platform, or the ML Platform as we like to call it. The ML Platform boosts our model-building and deployment capabilities by standardising ML workflows, streamlining the end-to-end development process and simplifying model deployment. Besides saving software engineering effort through centralising tooling, the ML Platform also reduces the time that our ML engineers spend on infrastructure tasks. As a result, our ML engineers can now iterate their ML models 2-3x faster than before.
What makes our ML Platform tick?
At the core of our ML Platform lies a carefully curated tech stack - an integrated suite of infrastructure tools, services, and libraries. It blends robust open source technologies with purpose-built, in-house components. Key open source tools include Kubernetes, Argo, and Metaflow, all seamlessly connected with leading ML frameworks like TensorFlow and PyTorch. We choose mature, community-driven solutions and actively contribute back where we can. This entire ecosystem is powered by AWS, running on EKS, and anchored by our data warehouse.
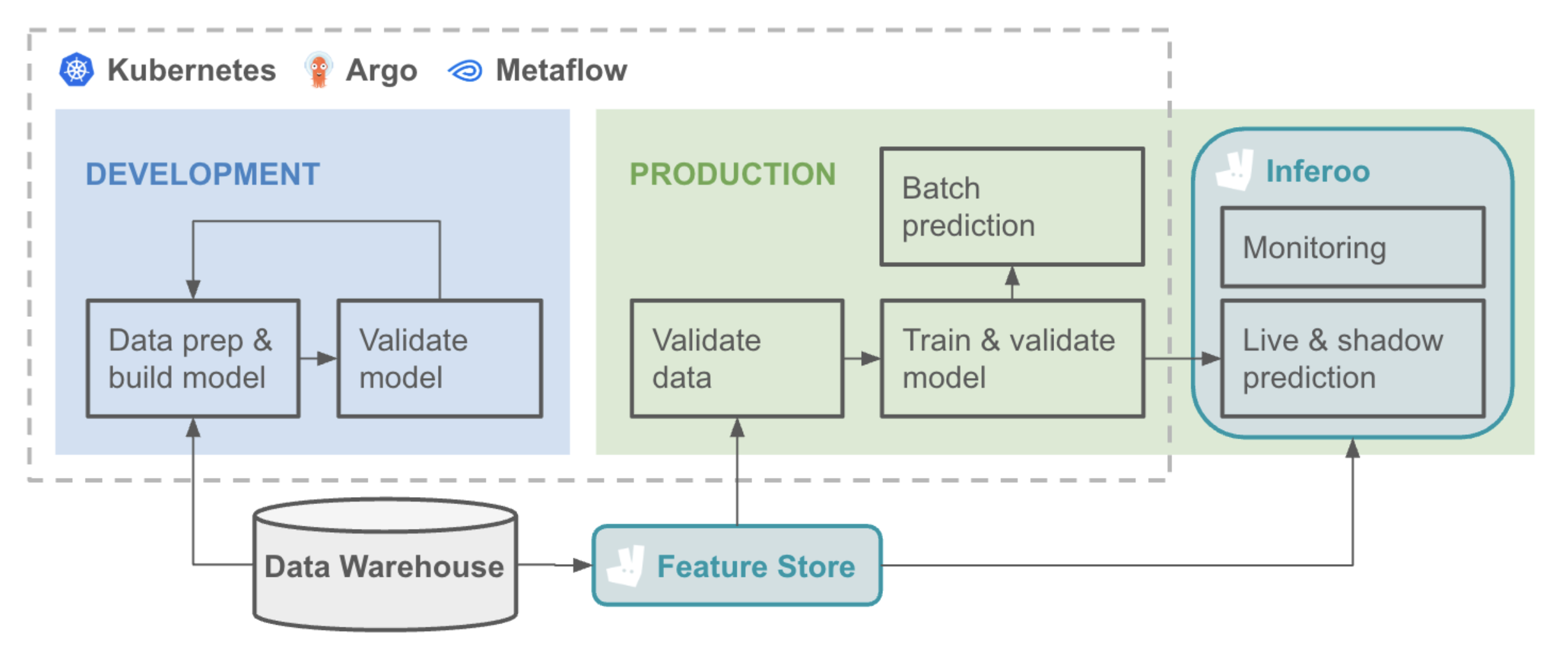
In the sections that follow, we’ll take a closer look at the key components that drive our ML Platform.
Metaflow
To give ML engineers seamless access to scalable compute on Kubernetes, we use Metaflow, a powerful Python library that helps break down complex model-building workflows into smaller, manageable jobs. These jobs are orchestrated by Argo, one of the backbone tools in our infrastructure. One of Metaflow’s biggest strengths is its flexibility. It allows engineers to move effortlessly between local development, staging on Kubernetes, and production deployment—helping teams iterate quickly as they experiment and scale. Recently, we added support for GPUs and distributed training, enabling faster training times and the ability to work with much larger datasets.
Inferoo
For models that require real-time predictions, we built Inferoo, our in-house inference solution. It serves models via both REST and gRPC APIs and currently handles over 1 billion requests per day. The motivation behind Inferoo was simple: to streamline model deployment and offer a consistent, reliable serving interface. Inferoo also integrates tightly with our Experimentation Platform, making it easy to run rapid A/B tests on different model versions. It also includes observability features for both batch and online models to keep an eye on model staleness, data drift and end-to-end model cost.
Feature Store
With Feature Store, we standardise how machine learning teams ingest and serve features for real-time inference. It supports batch ingestion from our data warehouse into Redis-backed online stores, with low-latency retrieval via a shared client library. Teams can manage feature definitions, materialisation pipelines, and versioning through a central Git-based registry. The first version of Feature Store focuses on enabling rapid experimentation and consistent deployment for live models. Future plans include real-time feature ingestion, feature sharing across teams, and support for offline training workflows.
How we work as a team
But even more important than the tech are the people who built all of it! Our team of software and ML engineers creates documentation, organises upskilling sessions, assists onboarding, maintains and monitors infrastructure, designs policies, selects external tooling and builds in-house apps such as our inference service and feature store. This year, the team is bringing all of our functionality together in an internal ML portal, which will serve as a centralised catalogue for all AI/ML models, offering visibility into model performance, system health, and operational cost metrics. Future iterations of the ML portal will also incorporate platform capabilities, to further simplify infrastructure creation and model deployment.
Three principles that we always keep in mind are automation, cohesion and self-serve:
- Automation: Our goal is to develop a platform that automates repetitive tasks, keeping ML engineers focussed on building models and minimising the risk of human error.
- Cohesion: We’re building a unified platform that emphasises the user journey. This platform needs to seamlessly integrate the entire model lifecycle, minimising the time teams spend connecting different frameworks and onboarding models onto services.
- Self-serve: We provide tooling that empower ML engineers to be self-sufficient, pushing the boundaries of technology without requiring the help of a software engineer at each turn. For example, we recently introduced support for GPUs and distributed capabilities for model training workflows. Both of these innovations significantly reduced model training time and enabled the handling of larger datasets.
What’s Next?
Deliveroo’s ML teams are constantly pushing the envelope, requesting new functionality for our ML Platform. We are already hosting some of the ‘next generation’ AI models, as well as supporting integrations between our homegrown models and externally hosted Large Language Models (LLMs). In addition, the governance of these new AI models is a big challenge that we are currently working very hard on to get right.
In future posts, we hope to share more detail on how we support these exciting new developments. So stay tuned for more updates as we continue to push the boundaries of what’s possible with ML and AI.
