

Best Open-Source AI Model: Experimenting With Phi-4 and Ollama in PostgreSQL

The emergence of lightweight, powerful open-source AI models like Microsoft’s Phi-4 and Meta’s Llama 3.2 has transformed the AI landscape, making it more accessible to developers.
Open-source AI models are artificial intelligence models whose code, weights, and architecture are publicly available for anyone to view, use, modify, and distribute. These open-source tools for AI applications are cost-effective, highly customizable, and allow complete control over the data flow, making them ideal for building privacy-focused, LLM-powered systems.
(If you want to learn more about this, we recently built a fully local retrieval-augmented generation (RAG) application using Mistral, another leading open-source model.)
However, identifying the best open-source embedding or generative model for your AI use case remains challenging. Running these models locally requires computational resources, technical expertise, and time to establish robust evaluation workflows. These hurdles can slow development progress and discourage adoption despite the advantages of open-source tools.
But it doesn’t have to be this way. In this blog post, you’ll learn how to simplify this process using Ollama and pgai. This will enable you to experiment with different models and quickly implement a RAG system using Microsoft’s Phi-4 in PostgreSQL.
Exploring Open-Source AI Tools: Phi-4, Microsoft’s Cutting-Edge Open-Source LLM
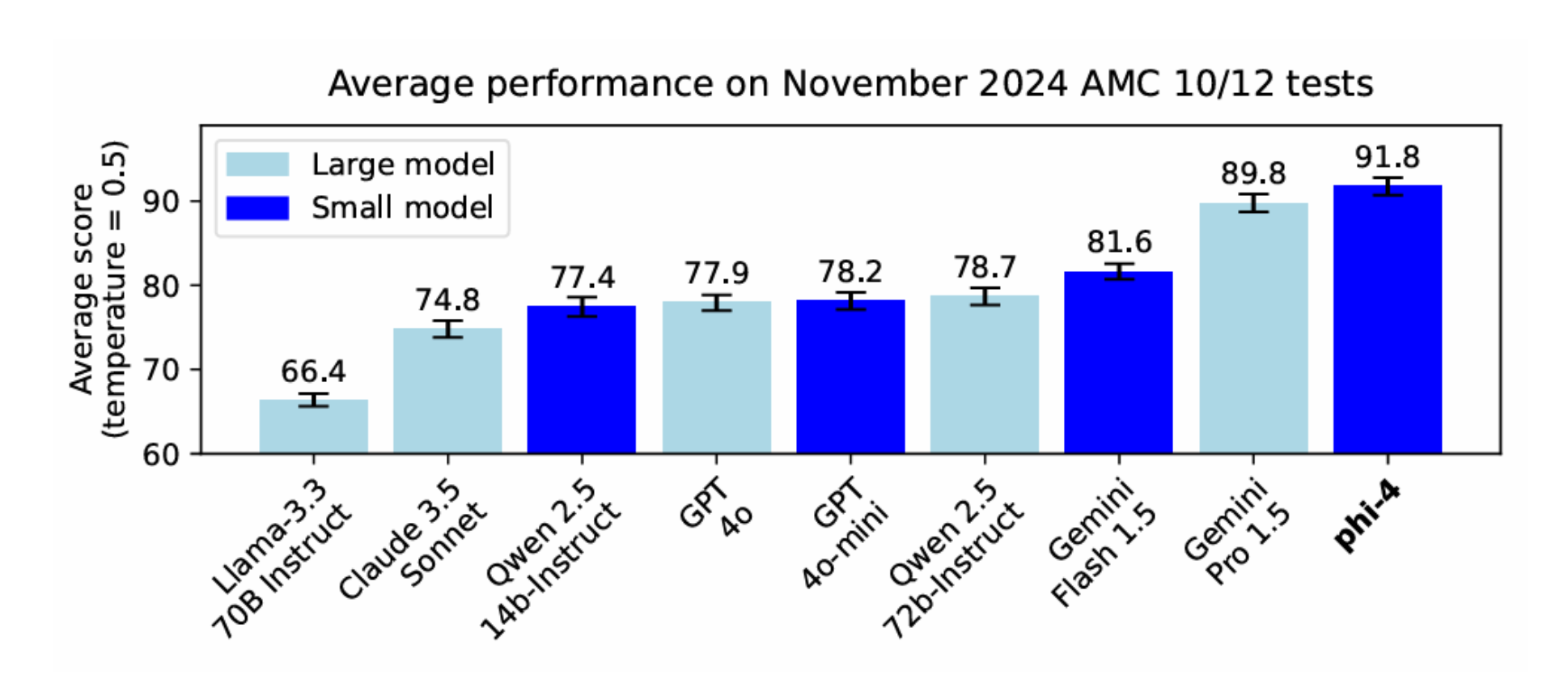
Phi-4, developed by Microsoft, is a compact, open-source large language model with 14.7 billion parameters, a 16K-token context window, and a size of just 9.1 GB. It is designed for research on large language models and use in general AI systems, primarily focusing on English.
Phi-4 excels in reasoning tasks, especially mathematics, outperforming even larger models like Gemini Pro 1.5. Its superior performance stems from its high-quality training data, including synthetic datasets, Q&A datasets, curated academic publications, and filtered public domain websites. This diversity makes Phi-4 a unique option for developers to experiment with, especially for those seeking accuracy and efficiency.
AI Model Experimentation: Integrating Ollama and Pgai
To fully appreciate the strength of combining Ollama and pgai, let’s first understand what each tool offers individually and explore the potential of their integration.
Ollama: Open-source models at your fingertips
Ollama (Omni-Layer Learning Language Acquisition Model) is an open-source tool that provides a unified interface for accessing and running embedding models and LLMs locally. Abstracting API complexities allows developers to focus on building applications without worrying about handling different model endpoints.
With Ollama, you can easily access Phi-4 and other models like Llama 3.2 and Mistral, making comparisons and experimenting straightforward. Additionally, Ollama simplifies downloading and managing embedding models, such as nomic-embed-text and mxbai-embed-large, which can be integrated seamlessly into your workflows.
echo "Downloading embeddings models for experimenting...."
ollama pull nomic-embed-text
ollama pull mxbai-embed-large
echo "Downloading generative models for experimenting...."
ollama pull phi4
ollama pull llama3.2Pgai: The AI engine within PostgreSQL
Pgai is an open-source PostgreSQL extension that integrates embedding generation and response workflows into the database. This approach eliminates the need for external pipelines, enabling seamless interaction with your data. Pgai supports various model providers, including Ollama, OpenAI, and Cohere, making it a versatile choice for AI development.
Why use pgai?
- Familiarity and ease of use
Pgai leverages PostgreSQL, a popular open-source database recognized as the “Best Database” in Stack Overflow’s Developer Survey for two consecutive years. Its SQL-based interface ensures that new or experienced developers can execute AI-related functions intuitively, smoothing the transition to AI development. Moreover, using PostgreSQL as your vector database ensures efficient data management by eliminating redundancy and allowing you to store your data alongside embeddings in a unified system.
Pgai abstracts the complexities of Ollama’s API, allowing developers to focus on building applications without technical hurdles. This integration ensures steady progress, whether you’re a novice or a seasoned engineer.
Before continuing, let’s set up our PostgreSQL and install the necessary extensions. This tutorial will use Paul Graham's essays as the source data. Pgai functions exist in the ai schema.
-- Install the pgai extension
CREATE EXTENSION IF NOT EXISTS ai CASCADE;
-- Configure at the session level the host from which Ollama is served
SELECT set_config('ai.ollama_host', 'http://host.for.ollama:port', false);
-- Create the source table
CREATE TABLE IF NOT EXISTS essays (
id BIGINT PRIMARY KEY GENERATED BY DEFAULT AS IDENTITY,
title TEXT NOT NULL,
date TEXT,
text TEXT NOT NULL
);
-- Load dataset from Hugging Face
SELECT ai.load_dataset(
'sgoel9/paul_graham_essays',
table_name => 'essays',
if_table_exists => 'append'
);
Pgai Vectorizer: Experiment with embedding models
Pgai also includes pgai Vectorizer, which automates embedding generation and synchronization with your source data using a single SQL command. This feature is invaluable for testing multiple embedding models, saving time and computational resources. Hence, you can use it with Ollama to configure vectorizers that use open-source embedding models and then compare their individual performances and performances with different generative models in any AI-powered system. You can read about the simple evaluation workflow we recently used to find the best open-source embedding model for RAG.
Here’s how to configure vectorizers for embedding models, nomic-embed-text and mxbai-embed-large. For more information about setting up the environment, please check out this pgai Vectorizer quick start with Ollama.
-- Configure vectorizer using nomic-embed-text
SELECT ai.create_vectorizer(
'essays'::regclass,
destination => 'essays_nomic_embed_embeddings',
embedding => ai.embedding_ollama('nomic-embed-text', 768),
chunking => ai.chunking_recursive_character_text_splitter('text', 512, 50),
formatting => ai.formatting_python_template('title: $title $chunk')
);
-- Configure vectorizer using mxbai-embed-large
SELECT ai.create_vectorizer(
'essays'::regclass,
destination => 'essays_mxbai_embed_large_embeddings', -- name of the view
embedding => ai.embedding_ollama('mxbai-embed-large', 1024),
chunking => ai.chunking_recursive_character_text_splitter('text', 512, 50),
formatting => ai.formatting_python_template('title: $title $chunk')
);
At this point, each vectorizer creates an embeddings table, named “destination_store,” which stores the generated vector embeddings. view, whose name is the destination parameter, that combines information from the source table, essays, and this newly created embeddings table
The following SQL function, generate_rag_response, facilitates vector search on a specified view linked to one of the generated embedding tables. It leverages the vector representation of the user’s query, created using the pgai function, ai.ollama_embed, and the same embedding model as the table it searches. This ensures consistency in representation and retrieves the most relevant chunks.
Then, the retrieved chunks and the user’s query are passed to the generative model alongside the user’s query for response generation using another pgai function, ai.ollama_chat_complete, which hits the /api/generate endpoint from Ollama.
CREATE OR REPLACE FUNCTION generate_rag_response(
query_text TEXT,
embeddings_view TEXT DEFAULT 'essays_nomic_embed_embeddings',
embedding_model TEXT DEFAULT 'nomic-embed-text',
generative_model TEXT DEFAULT 'phi4',
chunk_limit INTEGER DEFAULT 3
)
RETURNS TEXT AS $$
DECLARE
context_chunks TEXT;
response TEXT;
system_prompt TEXT := 'You are a helpful assistant. Provide accurate, well-reasoned responses based on the given context. If the context is insufficient to answer the question, say so.';
BEGIN
-- Perform similarity search to find relevant text chunks
SELECT string_agg(title || ': ' || chunk, E'\n') INTO context_chunks
FROM
(
SELECT title, chunk
FROM embeddings_view
ORDER BY embedding <=> ai.ollama_embed(embedding_model, query_text)
LIMIT chunk_limit
) AS relevant_posts;
-- Generate a chat response using Phi-4
SELECT ai.ollama_chat_complete
( generative_model,
jsonb_build_array
( jsonb_build_object('role', 'system', 'content', system_prompt)
, jsonb_build_object
('role', 'user'
, 'content', query_text || E'\nUse the following context to respond.\n' || context_chunks
)
)
)->'message'->>'content' INTO response;
RETURN response;
END;
$$ LANGUAGE plpgsql;
This function is versatile and supports experimentation with both embedding and generative models. To experiment with embedding models, you can fix the generative model while switching between different embedding-generated views. Conversely, to test various generative models, you can fix the embedding model and then alternate between different generative models.
Here are examples for each use case:
-- Experimenting with embedding models (mxbai-embed-large and Phi-4)
SELECT generate_rag_response(
'Give me some startup advice',
embedding_view := 'essays_mxbai_embed_large_embeddings',
embedding_model := 'mxbai-embed-large'
);
-- Experimenting with generative models (nomic-embed-text and Llama 3.2)
SELECT generate_rag_response(
'Give me some startup advice',
generative_model := 'llama3.2'
);
Conclusion
Open-source AI tools like Ollama and pgai make experimenting with embedding and generative models intuitive and efficient. By leveraging these AI tools alongside Microsoft’s Phi-4 and PostgreSQL, you can rapidly prototype and implement AI-powered applications while retaining complete control over your data. Whether comparing open-source AI models or deploying a robust RAG system, this stack allows you to innovate with ease and speed.
If you’re building AI applications, explore Timescale’s complete open-source AI stack or head to pgai’s GitHub repository to start bringing AI workflows into PostgreSQL—no need to leave your database. If you find it helpful, we would love your support—leave us a ⭐!
Further reading
Want to learn more? Check out these blog posts and resources about open-source AI models and tools:
- Stop Paying the OpenAI Tax: The Emerging Open-Source AI Stack
- Evaluating Open-Source vs. OpenAI Embeddings for RAG: A How-To Guide
- Which OpenAI Embedding Model Is Best for Your RAG App With Pgvector?
- Local RAG Using Llama 3, Ollama, and PostgreSQL
- Vector Databases Are the Wrong Abstraction
Source: View source


